

In 2025, businesses will be realizing they need to put real effort into appearing in AI models’ training data.
Why? With ChatGPT as the leader and up-and-comers such as Anthropic’s Claude and, notably, DeepSeek, billions of people will soon be talking to AI every day. That’s a lot of advertising space.
Therefore, it pays to position your brand such that ChatGPT mentions you often — and in a favourable light. Except, how would one do that? It’s decidedly unclear.
In this blog post, I will dive into several aspects of this fascinating, important, yet largely unexplored topic.
What is Generative Search Optimization?
To start with, let’s define the term in the title.
Generative Search Optimization (or, as some call it, Generative Engine Optimization)** is concerned with the visibility of a brand, a company, or a product in Generative AI apps such as ChatGPT, Perplexity, or DeepSeek.**
Interactions with these apps may be as short-lived as a single question-answer exchange or long conversations spanning weeks and hundreds of messages.
Why is Generative Search Optimization important?
ChatGPT is the 8th most visited website worldwide and its number of monthly visits is still growing fast. Referrals from AI apps such as ChatGPT will very soon become a significant percentage of all referrals. It means that they should be monitored, measured, and optimized for.
Importantly, there is evidence that for certain activities users prefer a conversational experience like ChatGPT to traditional search such as Google. According to a December 2024 NielsenIQ report:
Consumers are two times more likely to choose “Finding the Product I Need While Shopping” as their #1 desired AI solution.
At any point during these conversations, a brand , a company name or a product might be brought up — as in this example:
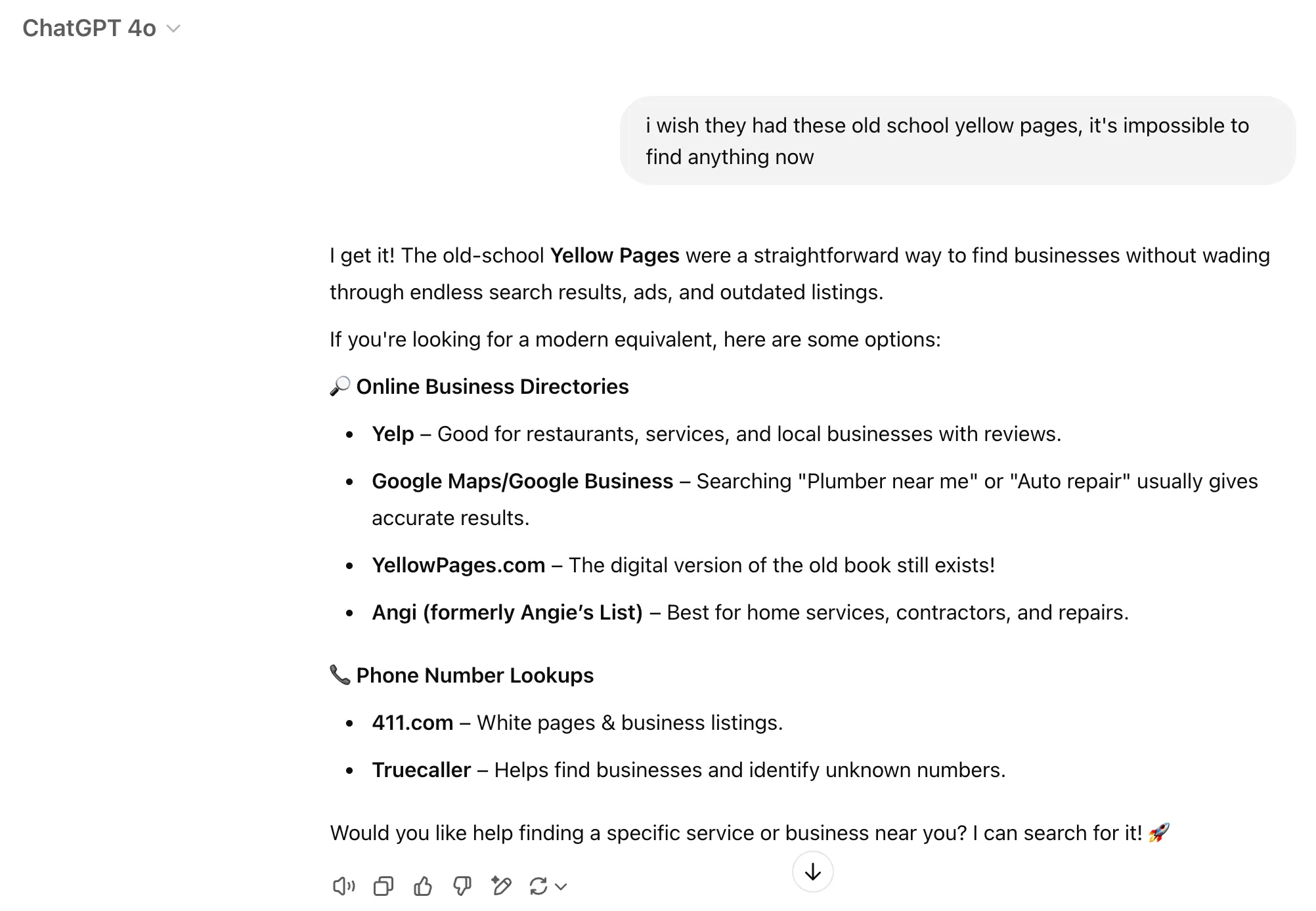
It is not obvious that Yelp or Angi would be the companies to link to here. At the same time it is clear that the response is a great free advertisement for these brands:
- Interaction is very natural and doesn’t feel like an ad at all
- Even though not explicitly stated, it is likely that the user will actually go ahead and check one of those services
The interesting question is: what exactly helped Angi grab such a great advertising spot? Is there a repeatable way for a brand to increase the frequency of appearing in such conversations? Is it possible to measure Return on Investment in Generative Search Optimization? We’ll try to dive into some of these questions in this blog post.
To make matters more complicated, simply rerunning the same conversation yields completely different results, this time with no brand mentions at all:
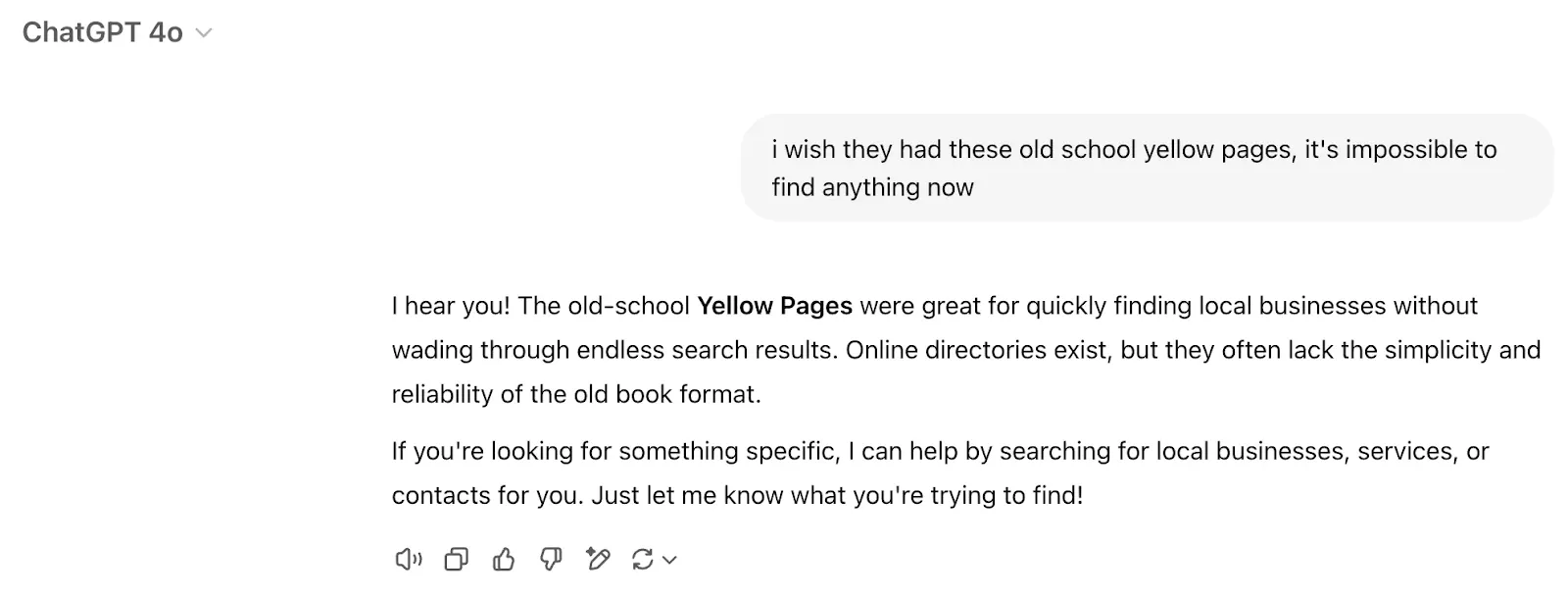
Sidenote: Both Perplexity and ChatGPT use web search results as the source for answers (the former to a much bigger extent). The effect of both will be disentangled as the blog post progresses.
What is the difference between GSO and SEO?
Many Search Engine Optimization best practices still apply when it comes to Generative Search Optimization. Some, however, are much less relevant.
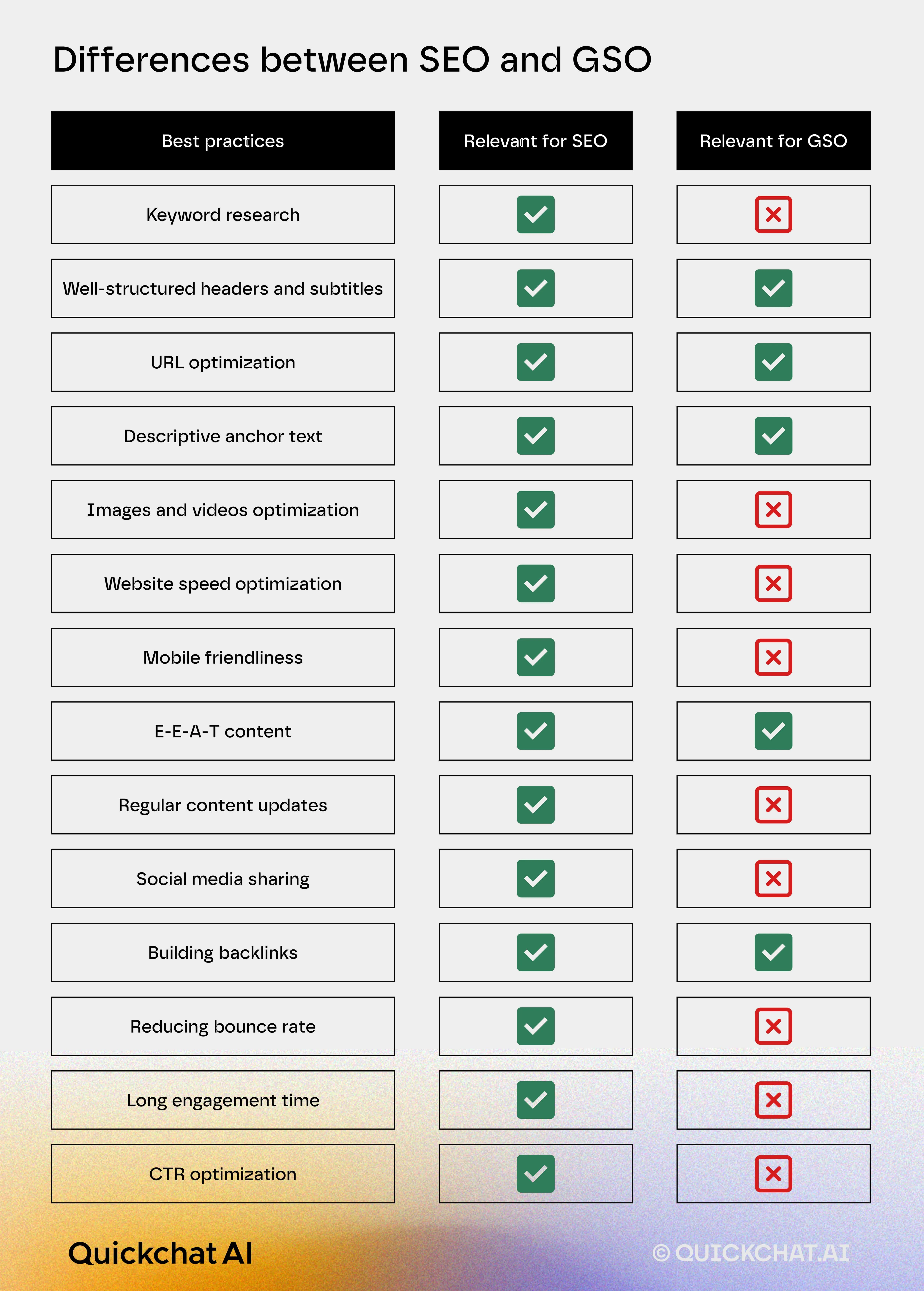
User interface
The key point to remember about the differences between SEO and GSO is how vastly different the end user experience is. Google (and other search engines) present us with a list of links to select from. In GSO-driven AI Apps like ChatGPT all content is presented in the form of a natural-sounding conversation.
Content served vs original text
How brands and products appear within search engine results can be fully controlled and is identical to the original copy created. At least for the time being, Google and other search engines are in the business of quoting, highlighting and linking to content rather than rephrasing it. The exact wording displayed by Google matches the original copy.
Within the natural conversation interface, Large Language Models summarize, rephrase and edit original content. Their responses aren’t mere quotes — they match the conversation flow and relate to the breadth of knowledge gained during training.
Let’s look at the following 5 example conversations with leading LLMs developed by OpenAI, Anthropic and DeepSeek.
Note: Testing was conducted using LLM APIs. For readability and a more representative user experience, we presented these outputs within the chat UIs of their respective LLM products. The initial user message was:“Looking to buy second-hand clothes in the UK, where should I look?” After the LLMs responded, a follow-up question was sent that’s visible in the screenshots:“I meant online, what’s the best app?”
Here’s the output of each tested LLM:
DeepSeek R1
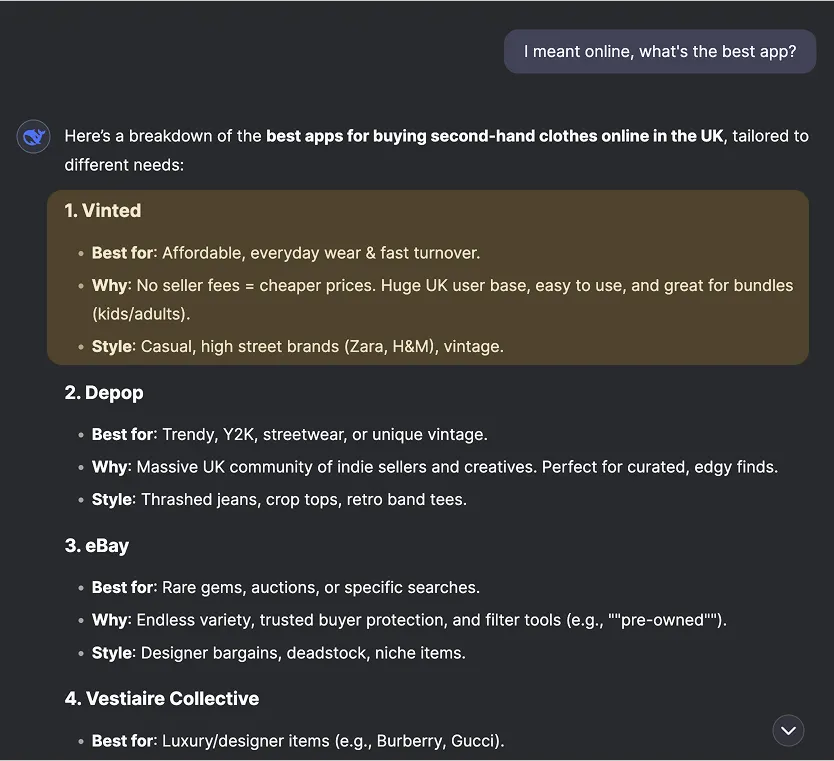
DeepSeek V3
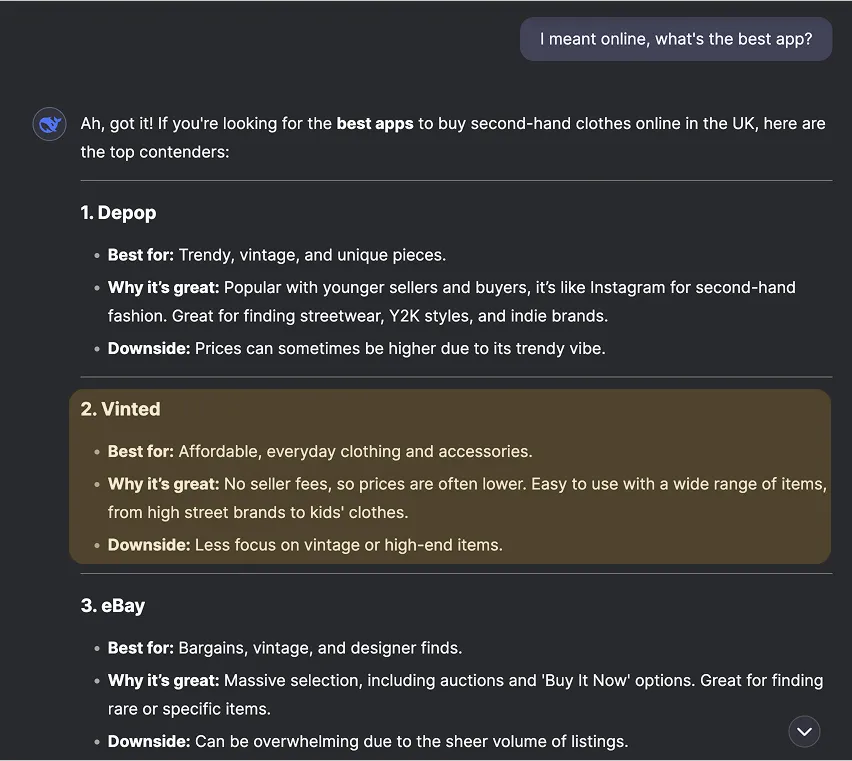
OpenAI o3-mini (o3-mini-2025-01-31)
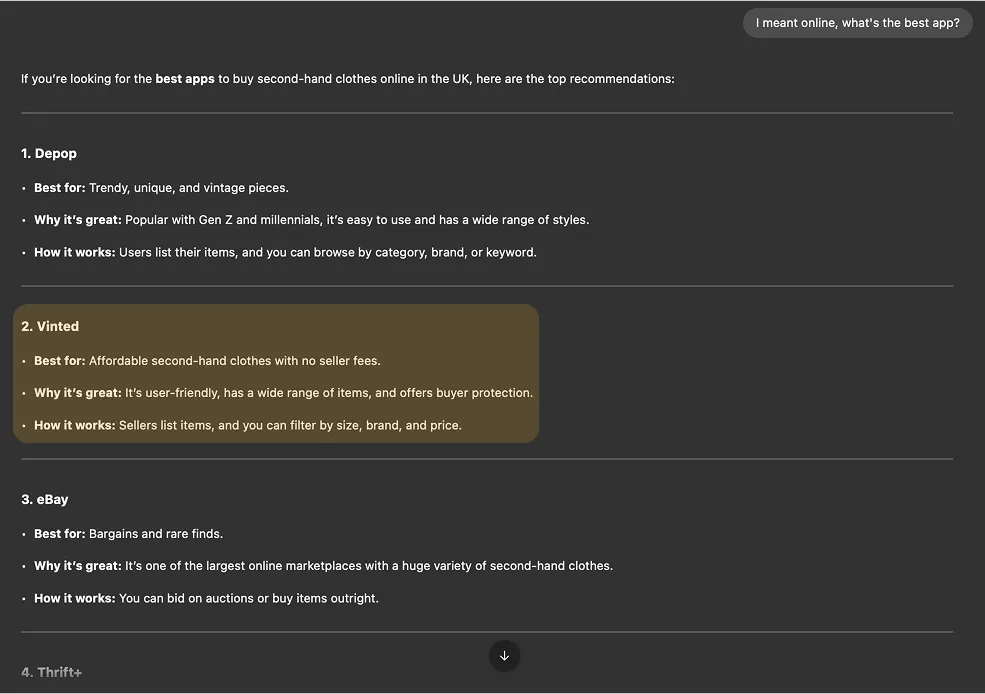
OpenAI GPT-4o
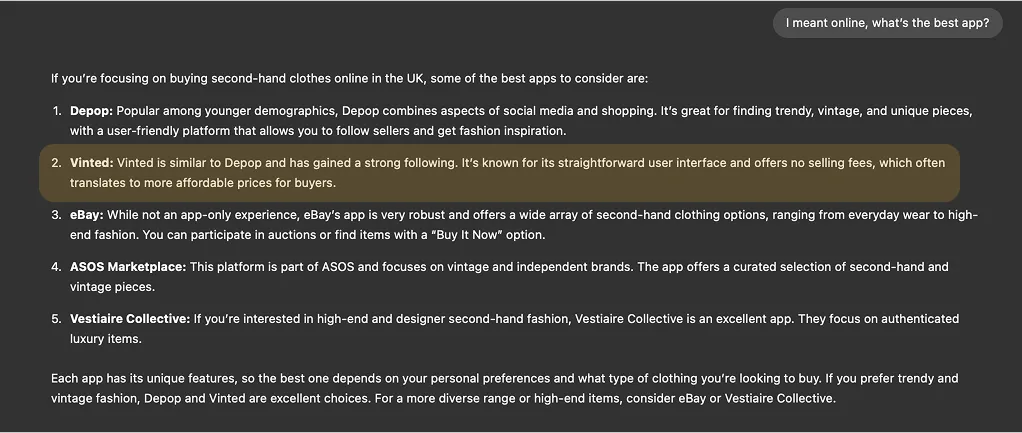
Claude 3.5 Sonnet (claude-3-5-sonnet-latest)
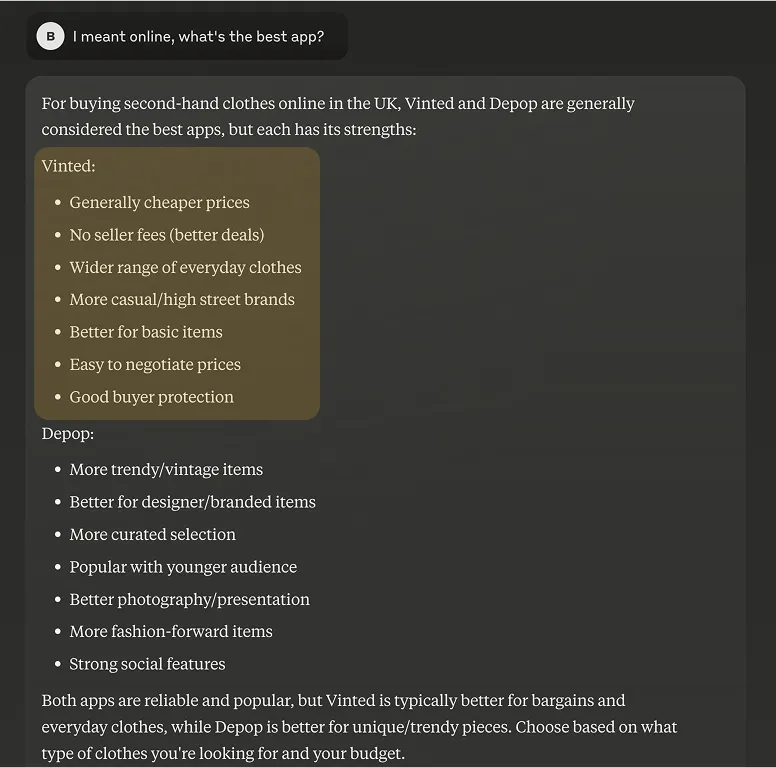
Across these example conversations, we can see several brands being mentioned and compared with one another. As an example, Vinted is often referred to as a more affordable version of Depop.
However, there are conflicting results regarding whether it is a place to look for vintage items.
Clearly, descriptions of brands are influenced by their official and original versions but the actual impression conveyed in conversation is different and unpredictable.
Measurability
User Interface differences also affect how easy it is to measure brand performance in GSO compared to SEO. Search engine results deliver a ranking which is a clear numerical measure of performance for a given search query. In the case of GSO, simply capturing whether a brand name was mentioned in a conversation might miss important details:
- How prominently the brand was mentioned
- Whether the brand was compared to competition and if the comparison was favorable
- Overall sentiment of messages and conversations mentioning the brand
Below is a straightforward example comparing how various models rank the world’s top 10 environmentally friendly companies. Simply measuring whether a company name has been mentioned doesn’t tell the full story. The mention could be very prominent (top of the ranking) or actively damaging (and worse than no mention at all) if portrayed as inferior to competitors.

Time lag
Any online content changes get reflected in search engine results within a few days, often much faster. When it comes to Generative Search Optimization, it might take months or over a year for new content to be reflected in a new, retrained version of the model.
LLMs training data cutoff date
Currently, OpenAI’s LLMs training data is significantly out of date , which results in pure LLMs not being aware of events that happened after their knowledge cutoff.
LLMs are trained on huge amounts of data which means that training is both expensive and time-consuming. DeepSeek’s recent revelations gave some hope that it might become cheaper but still, training LLMs will be considered a pricy endeavor for the foreseeable future.
The key question is: how often do LLMs get retrained? While we don’t have a definite answer, the table below shows the training data cutoff (knowledge cutoff) for the most popular OpenAI and Anthropic models (as of this post’s publication date):
Company Model Training data cutoff
OpenAI gpt-4o October, 2023
OpenAI o1 October, 2023
OpenAI o3-mini October, 2023
Anthropic claude-3-5-sonnet April, 2024
Anthropic claude-3-5-haiku July, 2024
As you can see above, OpenAI models are unaware of anything that has happened after October, 2023. If your company introduced any changes or new products in November, 2023 or later, ChatGPT, Perplexity or similar apps would not know about them.
The remedy to that was web search — the all-important feature introduced to the aforementioned AI apps. It likely uses several third-party search engines (Bing listed as one of them for ChatGPT) as well as their own scraped content.
The idea is brilliant in its simplicity. If the LLM isn’t aware of recent events, it should be able to run a web search and incorporate search results in its answer.
In practice, however, it is not that simple. The reason why we fell in love with LLMs in the first place is that they have read millions of websites, articles, and documents and are able to freely incorporate that nuance in their responses. When incorporating web search results, their content must take precedence over LLM’s own knowledge because they are sure to be up- to-date and correct.
As a result - and by design, the AI app becomes closer to a clever web search summarizer than a free-flowing agent that has read the entire internet. Sometimes, that’s just what users want but some will complain.
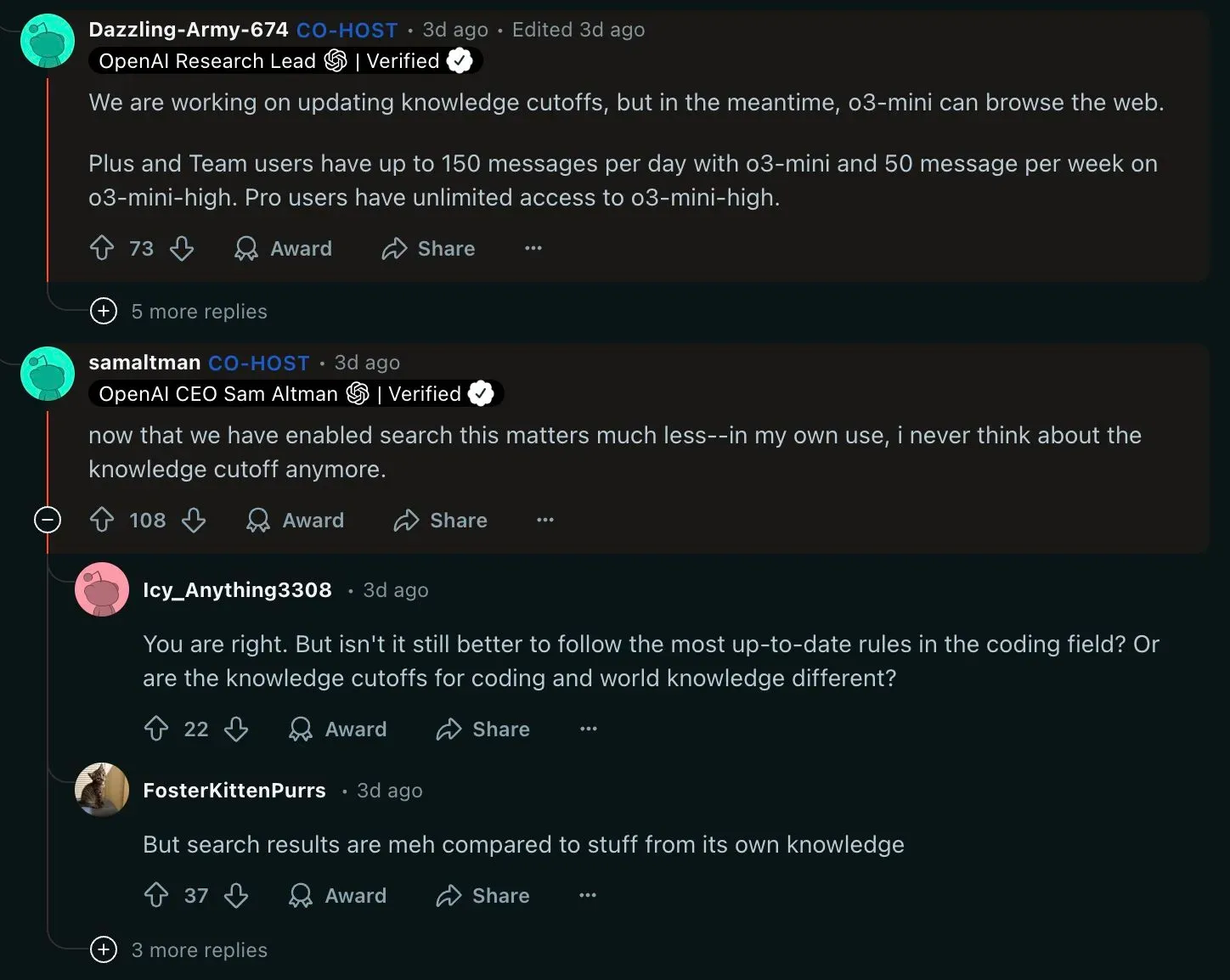
In a Reddit Ask-Me-Anything session, the OpenAI team confirmed they are working on updating knowledge cutoffs. But Sam Altman himself replied that in his own work, he never thinks about the knowledge cutoff anymore — thanks to ChatGPT’s Web Search feature. To which one Reddit user left a comment: “But search results are meh compared to stuff from its own knowledge”.
Paid ads
Today, search engines are ad-driven businesses while AI apps are free or offer subscriptions to users. That dynamic results in some key differences in how users perceive interacting with these products.
When googling, we are explicitly told that top results are affected by paid advertising, users can literally estimate how much money a company pays to Google if they click on their link. It is a very transparent system but makes it impossible for users not to take search results with a grain of salt.
At least for the time being (to the best of our knowledge), AI apps do not offer paid advertising. That creates a unique user perception. Users might complain about biases and inaccuracies in how LLMs portray the world but it is difficult to claim that a certain conversation or a certain claim by an LLM has been paid for in the form of an ad.
Will AI apps enter into the paid advertising model? I will discuss that subject in the final section.
Will ChatGPT replace Google?
The most likely scenario is that users will choose a solution that blends ChatGPT’s and Google’s features. Already today, we can see the two implementing one another’s features:
- ChatGPT often uses web search as an extra source
- Google often surfaces direct answers to users — eliminating the need for clicking on specific links
Finally, Perplexity AI, the up-and-comer in the space, is already today a fine-grained blend of Conversational AI and Web Search features. Perplexity’s UI is conversational but every AI response is heavily based on web search results, along with links, images, and videos.
Market fragmentation
In spite of the recent news that Google’s market share has dropped below 90%, it still clearly dominates the search engine market today. ChatGPT, as the leader of the GSO market, has a lower market share of below 60%. A higher level of fragmentation in the market for AI apps will make it more difficult to develop a universally effective strategy for positioning across all providers.
How do Large Language Models work?
What are gpt-4o, o1, o3-mini, claude, deepseek?
At the core of every Conversational AI app is a Large Language Model (LLM) which generates answers that are ultimately presented to the user. In today’s conversational AI apps, it is rare that users interact with the LLM directly. However, it is the LLM, or more precisely the data that it has been trained on, that is crucial to AI’s “opinions” , “preferences” and likelihood of mentioning one brand over another.
In very simple terms, every Large Language Model has read the entire Internet and, when prompted, is able to generate a summary on any subject. In reality, all LLMs do is look at the text and predict what the next token (word or part of word) should be. In that sense, even though it’s 2025 we should still be mind-blown that they work so well.
How to rank higher in Large Language Models?
Let’s expand on the list of GSO best practices listed earlier.
Well-structured headers and subtitles
LLMs are great at dealing with unstructured data. When fed text which is very disorganized, they will be able to get the gist and summarize it relatively.
That, in turn, means that poorly structured, unclear, or self-contradictory information is a lost opportunity to teach the LLM how you want your brand or product to be communicated to the outside world. During LLM training that will of course still be vetted against grassroots sources such as reviews, forums, personal blogs or Reddit. Clear and unified communication of brand values maximizes the chance of that wording being propagated by LLMs.
Common mistake: inconsistent communication of the one-line summary of the brand’s product across subpages, social media, different pieces of content.
URL optimization
Every bit of content is an opportunity to teach the LLM useful information as opposed to potentially confusing it.
Example: example.com/post/seo-best-practices clearly explains what the content behind the URL is.
Internal linking with descriptive anchor text
The same rule applies to links hidden behind descriptive text.
Common mistake: Read more here versus Read more in our blog post analysis of the DeepSeek model
Informative, original content (E-E-A-T)
Within the realm of SEO, it pays to create content with the sole purpose of driving traffic to your domain (even if it is only slightly related to your company or product). Generative Search Optimization works differently as all content is created for the purpose of being used in conversation. Unless explicitly asked by the user, the LLM is unlikely to provide the source or the company name on whose blog a particular bit of insight was originally found.
When it comes to content creation for the purpose of GSO, the focus should be on ways of portraying the company, product, and brand that are clear, unique, innovative, and consistent across all the sources that can ben found on the web.
Building backlinks
Traditional page quality measures such as the number of backlinks are being used to identify higher importance content and assign higher weights to it during LLM training. The work put into building up a network of backlinks referring back to your sites will increase the probability of your content being mentioned in responses generated by LLMs.
How to measure a brand’s performance in Large Language Models?
The concept of measuring how your pages rank against keywords important for your business is familiar. The equivalent of such a process in the realm of Generative Search Optimization is much more complex.
There is much more variability in conversations with AI apps than in search engine queries. And that’s in spite of the mind-blowing fact that 15% of Google search queries are unique. It’s impossible to map out all possible conversations that might be relevant to my brand and might lead to my brand being mentioned.
In the example below, it would be nearly impossible to map out that specific user query as a potential target for the Osborne brand. At the same time, the Jamón ham brand just missed the mark and has not been mentioned specifically.
Another complicating factor is that LLM brand mentions are very sensitive to the specific wording or the specific content of the conversation. Our yellow pages conversation quoted earlier is a good example of the unpredictability of LLM results.
It is, however, an undeniable fact that millions of people are talking to ChatGPT, Perplexity, and similar apps every day and conversations bringing valuable traffic to various brands do occur — and will only grow in numbers.
LLM brand measurement workflow
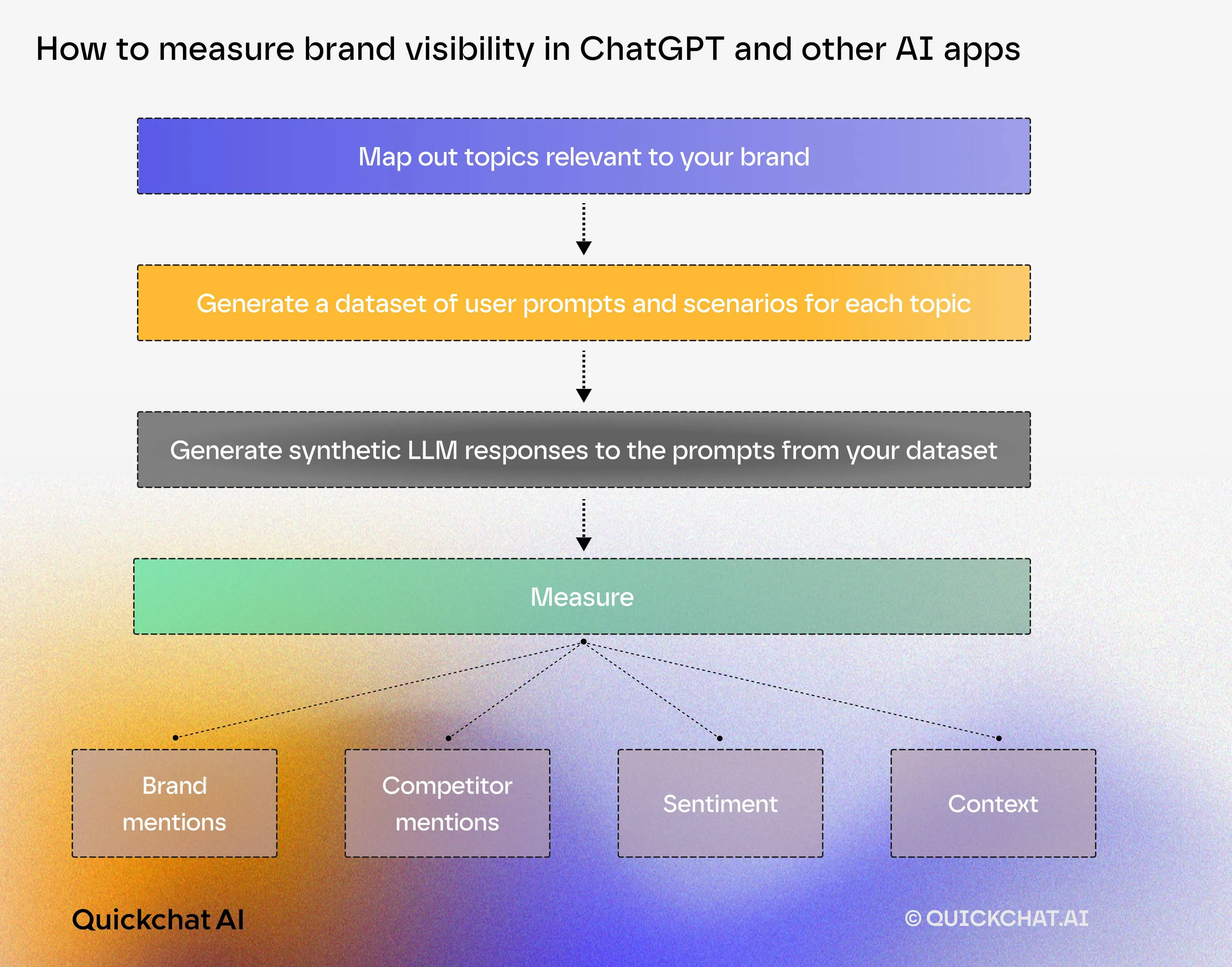
A workflow we suggest for measuring a brand’s performance in LLMs is based on prompt and conversation simulations:
- Map out topics relevant and adjacent to your brand.
- Generate a dataset of plausible prompts and conversation scenarios for the given topic.
- Generate synthetic LLM responses and conversations based on the dataset of prompts and scenarios.
- Measure the following for dataset items:
- Brand mentions and their prominence
- Competitor mentions
- Sentiment of brand mention
- Context of brand mention
The above metrics can be quantified and measured across time and various LLM versions and providers.
How does ChatGPT work?
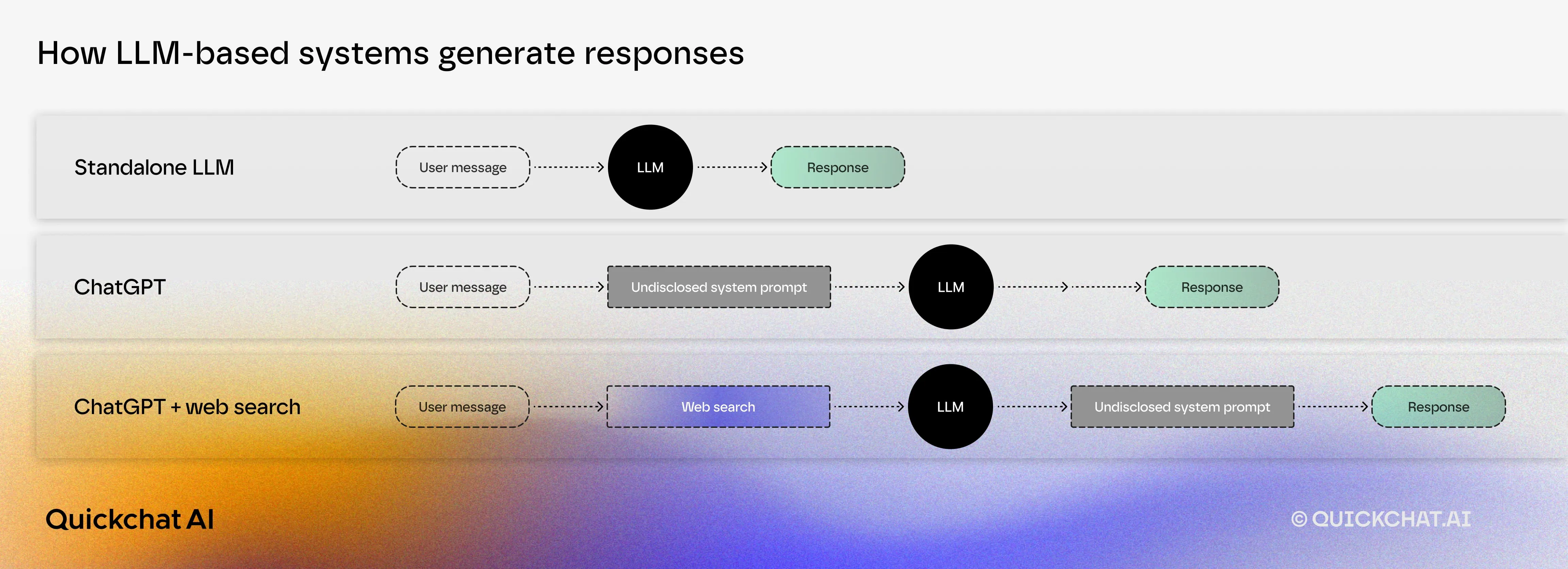
So far, we have been discussing Generative Search Optimization in the context of the Large Language Model itself. In that scenario, input is fed directly into the LLM:

ChatGPT, as available in the App, is an LLM whose inputs are most likely enriched by some sort of a prompt. It is also likely that the LLM itself is slightly different (e.g. finetuned) from the raw LLM available via API.
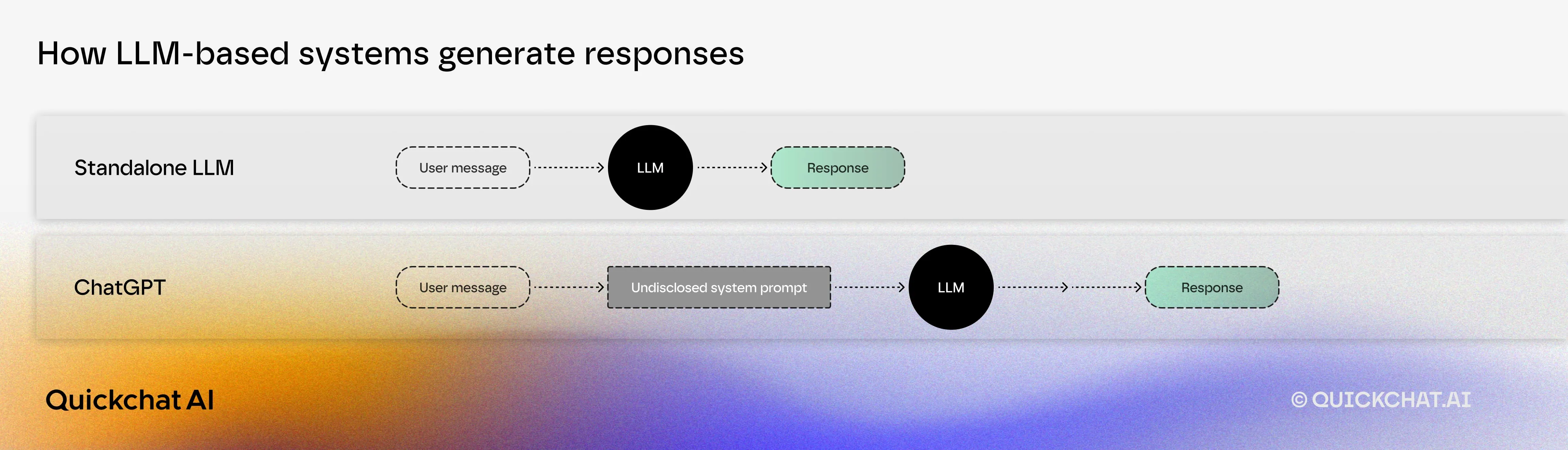
Today, AI apps such as ChatGPT or Perplexity use web search as a basis for their answers. In the case of Perplexity, the use of web search is more prevalent.
Conclusions:
-
Brand visibility in AI Apps is affected by the following components:
- Component 1: LLM (governed by Generative Search Optimization)
- Component 2: Web search (governed by Search Engine Optimization)
- Component 3: Undisclosed prompt and finetuning (which highlights the need for end-to-end testing by interaction with the app itself)
-
The prevalence of web search versus pure LLM-based answers will be the indicator of the relative importance of GSO versus SEO.
-
The existence of component 3 highlights the need for end-to-end testing with the actual apps. Our assessment, however, is that components 1 and 2 will have the dominant effect. Any tests, measurements, or trends discovered based on 1 and 2 only, will not be significantly different from what end-to-end measurements would have shown.
What does Generative Search Optimization mean for e-commerce and
traditional media?
The most significant difference between AI apps and search engines is the user interface of surfacing straight answers rather than links to primary content.
Many artists and [publishers](https://www.reuters.com/technology/artificial- intelligence/openai-faces-new-copyright-case-global-publishers- india-2025-01-24/) have protested OpenAI and other LLM vendors training models on copyrighted data. In very simple terms, LLMs can give users direct answers from copyrighted content. In the past, using traditional search engines, users had no choice but to click on links to original sources to get access to content. That provided a source of revenue (paywall or running ads) to content creators.
From a Wikipedia essay on Large Language Models and copyright:
An LLM can generate copyright-violating material.
The copyright status of LLMs trained on copyrighted material is not yet fully understood.
On the other hand, there are initiatives aimed at helping LLMs be trained on
the websites’ content. In a similar fashion to the robots.txt file which
helps Google crawlers navigate sites, an llms.txt file has been
proposed to serve the same purpose for crawlers
gathering LLM training data. The proposal comes from Jeremy
Howard, co-
founder of fast.ai who previously founded
FastMail and served as President at
Kaggle.
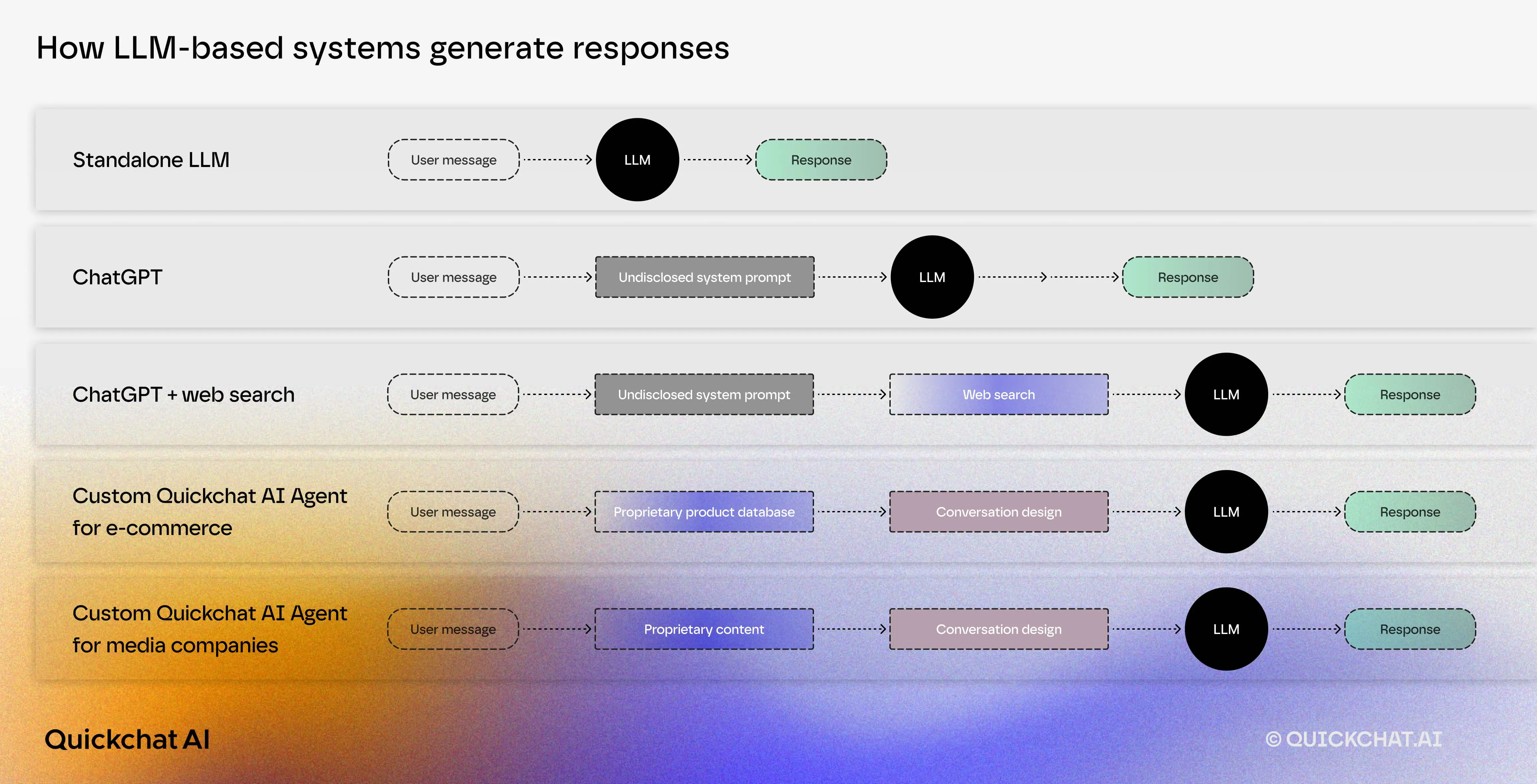
Example businesses for whom the decision whether to help or prevent LLM scraping is particularly consequential are e-commerce websites and traditional media. Both of them strongly rely on their ability to customize the user’s journey on their site.
Customized solutions include additional components which allow for incorporating businesses’ understanding of their users and proprietary data. For example, the diagram below depicts architecture outlines of custom AI Agents we would develop at Quickchat AI for:
- E-commerce businesses (an AI Agent that learns about customer’s preferences via conversation and recommends products based on a proprietary products database)
- Media companies (an AI Agent who answers users’ questions and holds discussions based on proprietary content available on a news site)
How to rank higher in ChatGPT?
With ChatGPT, Perplexity, and similar apps rising in prominence, not only traditional SEO metrics should be tracked and optimized but also LLM-based GSO metrics , as described in earlier sections. The relative importance of the two will depend on decisions made by AI app providers regarding the use of pure LLMs versus the web search feature.
One possible scenario is that starting in 2025/2026, there will be a strong push from top LLM labs to bring the knowledge cutoff as close as possible to the present. That would be a natural step that solves issues described in the previous section and establishes LLMs as a technology to replace traditional web search rather than use it.
However, the fact that today’s knowledge cutoffs are so far off suggests that technology and processes are not ready yet for LLMs to be aware of events from, say, 1 week ago. My prediction is that this problem will not be resolved this year. Most likely, it is surprisingly risky and time-consuming to add a few more months of data and retrain the model because of all the final touches that happen after training has finished.
A different direction which seems more likely today is that AI Apps will become more agentic and their use of tools such as web search will be emphasized and expanded. While conversations with AI might become the great new interface for searching on the web, many users who have loved LLMs for how they are different from web search might be disappointed.
Whichever is the more likely scenario, LLMs are here to stay and SEO, while still important is no longer enough. Every marketing manager should be tracking GSO metrics and cross-checking if the wording LLMs use to describe their brand, product and values is in line with their expectations. If you would like to learn more, feel free to reach out to us at quickchat.ai/contact-us.
The future of Generative Search Optimization
Paid advertising in AI apps
How could paid advertising work in ChatGPT? How exactly could a brand pay to appear in a response to a message like the one below? What would be the equivalent of pay-per-click?
These are fascinating questions, especially if we take into account how Large Language Models work under the hood and how unpredictable their outputs are.
Today, OpenAI could in theory measure how many times a particular brand has been mentioned in user conversations. Would it be possible for a company to pay to increase their brand presence by 10%? What effect would that have on the brand presence of their competitors?
Would it be possible for a brand to pay to ensure that a particular wording is always being used when it is mentioned? Think of it as imposing a brandbook on an LLM.
Two 2024 research papers from University of Maryland & Google Research sketch out basic ideas for LLM-based advertising:
For a less technical introduction, I recommend this blog post.
Research models
The launch of DeepSeek kicked off a new wave of LLMs called research or thinking models. Research models take longer to generate their answers (up to a few minutes) but the generation process involves several steps diving into a topic, taking steps back, and refining the approach. Research steps could also include several web searches which might potentially significantly increase the number of pages the LLM consults for generating a single answer. From the UX/UI perspective, it is unclear how often users will actually be willing to wait a few minutes to receive better-researched answers.
What could this mean for Generative Search Optimization and SEO? Research models iterating on web search and broadening its scope will put less emphasis on top SEO results and allow for less SEO-optimized content to be surfaced.
AI Agents
A natural and widely spoken-off extension of research models is agentic models that can take actions in the real world. Imagine an AI app that not only googles relevant results for you but also proactively takes actions such as pre-ordering items, conducting price negotiation, or requesting additional information.
Optimizing your website for AI Agent access creates yet another set of requirements compared to our SEO and GSO considerations. Those will include:
- Fast response times (AI Agents need to be able to complete tasks in real time)
- Coherent markup and metadata (clear, natural language explanations for HTML elements such as images, buttons, menus)
- Providing a clear API for interacting with the site’s key functionalities
Further fragmentation of the AI app market
My prediction is that OpenAI will struggle to keep ChatGPT as the leader in all AI chat use cases (entertainment, learning, online shopping, research, news consumption, etc.) while solving fundamental issues like the knowledge cutoff or LLM inference efficiency. That will open room for up-and- comers in the field to come in and carve out segments of ChatGPT’s market in specific use cases.
One example of such a specialised app is Gralio, a software search and comparison platform. They curate their own index of software products and data sources, and then use LLMs to interpret and present that information to customers. That approach shields them from both knowledge cutoff issues and reliance on traditional web search. As apps of this kind take over more of ChatGPT’s traffic, individualized brand presence efforts will be a must.
Today’s users who have got used to starting their research, shopping, or news consumption journeys with ChatGPT might expect similar experiences with other vendors. A useful tactic for large e-commerce stores or news outlets will be to mimic and improve on the ChatGPT experience on their own site using their own conversation design and proprietary data.