

Generative language models (you may have heard about ChatGPT, GPT-3, Cohere, GoogleLamda, BERT, GPT-2, etc.) produce text.
Given some text as input, they are able to make really good guesses as to what comes next. We use those at Quickchat as fundamental components of our chat engine powering Emerson AI and our business products.
Interestingly, generative language models don’t write out text word by word or letter by letter but rather token by token.
In this blog post, I will have a look at tokens, entropy, compression and finally leave you with some unanswered questions.
Why tokens?
The basic answer is fairly obvious — there are too many words in existence, too few letters and tokens is a good middle ground.
When training Machine Learning models representation is key — we want to present the model with data in a way that facilitates picking up on features that matter.
OpenAI released a very neat tool that lets you play around with text tokenization that they use for GPT-3.
Let’s use it to gain some intuitions.
 Tokenization of a sentence in English containing a made-up word
Tokenization of a sentence in English containing a made-up word
Yes, I made up a word.
There is no dictionary in the world that has overpythonized as an entry. Google actually claims the word does not appear anywhere in the vast Internet.
 Definite proof that overpythonized is a made-up word
Definite proof that overpythonized is a made-up word
And yet somehow you and I have a rough idea about what overpythonized could mean. That’s because we know words such as overparametrized — and we know what Python is.
That’s the main idea behind subword tokenization.
Your model can learn nothing about overpythonized from its training data but there is a lot to learn about over, python and ized.
Let’s try one more thing. 👇
 Loosely translated into Polish
Loosely translated into Polish
In the above, “I think your codebase is exceedingly overpythonized” has been loosely translated into Polish. As expected, many more tokens are now necessary — we will talk more about that in a minute.
But another tragic thing happened here. przepytonowany has been tokenized into pr, z, ep, ython, ow and any.
prze, believe it or not, is a very common word prefix in Polish.
However, the tokenization we’re using is based on English text.
That’s why python does not happen to be a token in this case, which means that as far as the model is concerned our sentence has absolutely nothing (2) to with the programming language (or the 🐍).
Text that’s cheapest to feed into GPT-3
Tokenization is a type of text encoding.
There are many different ways to encode text and many different reasons why you may want to do that. The classic example is encoding text in order to compress it. The very basic idea is to assign short codes to symbols that are often used. That forms the basis of Information Theory.
It’s interesting to think about what tokenization (the encoding we described above) has been designed to optimise for. Loosely speaking, tokenization is supposed to help language models like GPT-3 perform better.
Of course, it isn’t anywhere near globally optimal, as it should have been trained jointly with the language model itself while in reality it is treated as an external component that the model has to work with.
Surely, tokenization has not been optimized for minimizing the number of tokens per word, which is something to consider given that you are being charged for usage of some of these models per token rather than per character. Let’s see what kind of text is cheapest to feed into GPT-3 (3):
TEXT TOKENS PER WORD:
| Source/Title | Value |
|---|---|
| Facebook’s Terms of Service | 1.17 |
| Leonardo Di Caprio’s Oscar acceptance speech | 1.20 |
| 🇬🇧 Wikipedia article on Philosophy (Simple English) | 1.20 |
| Harry Potter and the Philosopher’s Stone (first chapter) | 1.28 |
| OpenAI’s GPT-3 paper | 1.29 |
| I think your codebase is exceedingly overpythonized | 1.43 |
| Shakespeare’s Sonnet 18 | 1.46 |
| 🇬🇧 Wikipedia article on Philosophy | 1.46 |
| Kanye West’s Stronger lyrics | 1.49 |
| Queen’s Bohemian Rhapsody lyrics | 1.58 |
| Taylor Swift’s Shake it off lyrics | 1.60 |
| Luis Fonsi Despacito lyrics | 2.26 |
| 🇪🇸 Wikipedia article on Philosophy | 2.32 |
| 🇮🇹 Wikipedia article on Philosophy | 2.48 |
| 🇩🇪 Wikipedia article on Philosophy | 2.88 |
| Wasz kod jest zdecydowanie przepythonowany | 3.40 |
| 🇵🇱 Wikipedia article on Philosophy | 4.08 |
| 🇰🇷 Wikipedia article on Philosophy | 8.67 |
| 🇨🇳 Wikipedia article on Philosophy | 13.13 |
What is the intuition here? Fewer tokens per word are being used for text that’s closer to a typical text that can be found on the Internet. For a very typical text, only one in every 4–5 words does not have a directly corresponding token.
Entropy
Let’s think again about an encoding whose goal is to compress text. The classical example here is to encode the English language and people have already figured out how to do that optimally (Huffman coding):
| Character | Frequency | Code |
|---|---|---|
| Space | 16.2% | 111 |
| e | 10.3% | 010 |
| o | 8.2% | 1101 |
| t | 6.9% | 1011 |
| a | 6.2% | 1000 |
| s | 5.8% | 0111 |
| n | 5.5% | 0110 |
| r | 5.0% | 0010 |
| i | 4.0% | 11001 |
| u | 3.5% | 10101 |
| d | 3.4% | 10100 |
| c | 3.3% | 10010 |
| l | 2.6% | 00110 |
| h | 2.4% | 00010 |
| p | 2.2% | 00001 |
| m | 1.9% | 110000 |
| y | 1.7% | 100111 |
| g | 1.4% | 001111 |
| , | 1.3% | 001110 |
| f | 1.3% | 000111 |
The above table shows the optimal binary code to assign to each of the top 20 most common symbols. Most common based on… what? Great question!
Huffman coding tells us how to optimally encode symbols to compress the English language but we need to define what we mean by the English language. The table above is based on a sample from Facebook’s Terms of Service referenced earlier.
So, the assumption here is that all English language that may come our way is going to be something like the sample we used (4).
It’s interesting to think how while Huffman coding gives us optimal encoding with compression in mind, there must be an optimal tokenization algorithm with the “GPT-3, predict the next token” task in mind. Given some text representative of the English language and a language model architecture (say, a Transformer) it would find the optimal tokenization to use. That task would be extremely difficult because everything would need to be trained jointly therefore, among many other complications, structured to be differentiable. So let’s leave it there. 🙃
Going back to the topic of compression, since we know how to find optimal encoding for any symbol frequency distribution, a single quantity, Entropy, defines the minimal theoretically possible number of bits per symbol for a given data source - say, the English language. The general intuition here is as follows: the more uniformly symbol frequencies are distributed, the more bits per symbol we need.
A classic example here is results of a biased coin flip as a data source. If the coin is well-balanced (tails 50% of the time) you need to transmit 1 bit per coin flip regardless of how much you tell me about that coin beforehand. If, however, you tell me ahead of time that it’s a magic coin that’s always heads - I need zero bits of information from then on to exactly know all future outcomes.
The unanswered question
The entropy formula tells us exactly how the average number of bits per symbol for a data source can be calculated (assuming optimal encoding):
 Entropy is equivalent to Average Number of Bits per Symbol
Entropy is equivalent to Average Number of Bits per Symbol
A symbol of frequency p will be encoded with approximately -log(p) bits. Multiply that by its frequency and we get a formula for each symbol’s contribution to entropy: -p * log(p). The above formula is the sum of all those contributions.
It’s interesting to think about what makes a symbol distribution have a higher or lower average number of bits per symbol. Imagine a source generating one of 100 symbols, each with the same frequency of 1%. Each of these symbols would contribute -0.01 * log(0.01) = 0.02 to entropy.
What about a source with 4 symbols with frequencies 70%, 10%, 10%, 10%? The 10% ones would contribute 0.10 while the 70% one only slightly more: close to 0.11. There’s a trade-off there — it is possible for a much more frequent symbol with a shorter code to contribute almost the same amount.
That brings us to the final question: what’s the frequency of a symbol that contributes to entropy the most?
 Contribution to entropy vs symbol frequency
Contribution to entropy vs symbol frequency
It’s 36.79%!
Why that particular number? Well, that’s part of the unanswered question I was getting at.
The amazing fact is that, if you work out the math, that number is 1 / e exactly. Yes, e as in f(x) = e(x) is at every point equal to its derivative. And e as in if you invest $1,000 with a 100% annualized return that compounds infinitely often you’ll end up with e times $1,000 (approx. $2,718). And e as in:
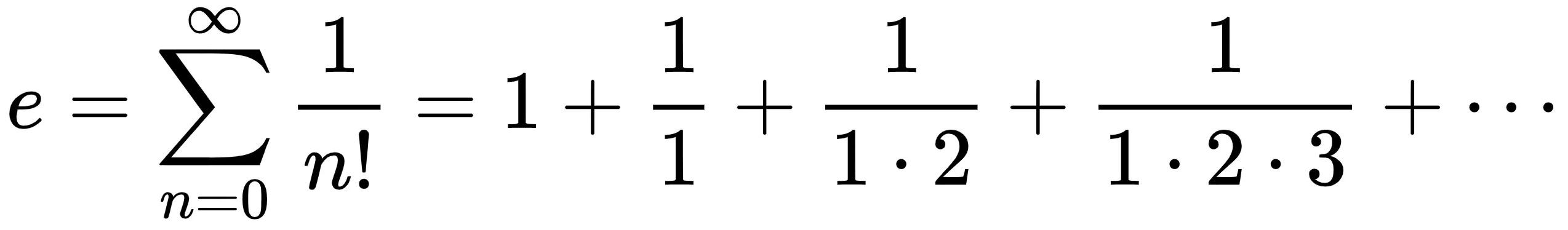
If you can show me an intuitive connection between e and the frequency of a symbol that maximally contributes to the entropy of a data source — you’ve solved it!
Btw, I don’t have an answer, none of the people I’ve asked over the years gave me one and an answer more convincing that the derivation above likely does not exist. 🙃
At Quickchat, we love solving hard technical problems and thinking from first principles. If you found any of the above interesting and would like to dive deep into how it relates to building world-class conversational AI, apply to work with us!
- Vocabulary used by GPT-3 contains 50,257 tokens. The Oxford Dictionary has over 150,000 entries. The total number of words in usage is hard to estimate but certainly much higher than that.
- Strictly speaking, if ython is a token then it may have been seen in training data in a somewhat relevant context. One possible way is by the word jython (a Java implementation of Python) being tokenized into j and ython. So representation of the token ython would, after all, have at least some context related to Python. But it is of course much less accurate than what could be achieved with correct tokenization.
- What I have in mind here is cheapest on a _per-word_ basis. Also, the total cost would include not only tokens _fed into_ GPT-3 but also tokens _generated_ by it.
- In general, comparing compression algorithms is only possible in the context of a dataset that they were to compress. Sillicon Valley's Weissman Score (which, by the way, was made up at the request of the series' producers), without a diverse enough reference data set agreed upon by all, wouldn't be feasible as a universal comparison metric.