

Shoutout to Quickchat’s AI team for the awesome technical analysis: Mateusz Jakubczak and Arek Góralski!
DeepSeek is one of the latest models gaining attention as a potential alternative to GPT-4o. But how practical is it? We looked at its performance, costs, and real-world usability to understand whether DeepSeek is truly a game-changer or if the hype outpaces reality.
What Is DeepSeek R1? Pros, cons, and “thinking” copilots
DeepSeek R1 is a 671-billion parameter model built for reasoning. Instead of optimizing for fast responses, it uses inference-time scaling techniques, which means it takes extra time to generate more structured and logical answers. This makes it unsuitable for customer-facing applications (like website chatbots) where instant replies are essential, but promising for tasks where quality and reasoning matter more than speed.
Some people will happily wait.
At Quickchat AI, we’re working with Fortune 500 companies to develop, among other LLM-based solutions, AI copilots that prioritize thinking over speed. Often, employees don’t need an immediate response. They need a well-structured answer that supports complex decision-making and don’t mind waiting for one for a few minutes.
AI copilots powered by models like DeepSeek R1 can explain why they arrived at a conclusion, making them far more valuable in high-stakes environments where AI reasoning needs to be transparent and verifiable.
AI moves beyond basic automation and becomes an active assistant in decision-making rather than just a tool for retrieving quick responses.
Alongside R1, DeepSeek also has DeepSeek V3, another 671-billion parameter model, but structured as a Mixture of Experts (MoE). Unlike R1, which activates all parameters at once, V3 selectively engages only parts of the model per request, making it more efficient in some cases. The bad news is that both models are extremely large and require significant infrastructure to run.
Is it actually that cheap?
A year ago, running a high-quality AI model locally seemed impossible.
Today, it’s possible, but still expensive. Some users have successfully run DeepSeek on 8 Mac Minis, proving that local deployment can work.
But this setup cost $20,000 and was very slow, showing that while DeepSeek is open-source, real-world deployment isn’t free.
For full-scale performance, DeepSeek R1 or V3 requires serious infrastructure:
- Both models are ~400GB, meaning you need 8xA100 GPUs, which costs $30k/month on Google Cloud Platform (GCP).
- Quantization (reduced floating-point accuracy) can reduce the model size to 131GB, but even then, 2xH100 80GB GPUs are required, costing $7k/month on GCP.
- A lower-cost alternative is Hetzner’s 512GB RAM + RTX 6000 Ada 48GB VRAM, which costs $1k/month, but performance is significantly slower.
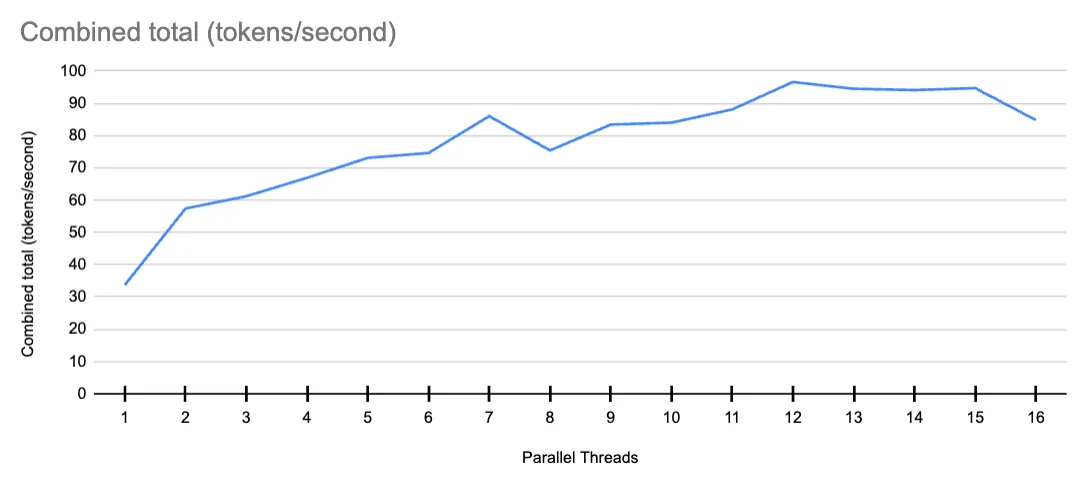
DeepSeek V2, which is a smaller model at 16 billion parameters, offers a cheaper and more scalable option. In real-world tests — run on GCP G2-standard-8 (8 vCPU, 32GB RAM) + NVIDIA L4 GPU (24GB VRAM) — it reached 100 tokens per second but stopped scaling beyond 12 threads, meaning adding more resources beyond that doesn’t improve performance.
The actual cost per million tokens for DeepSeek V2 (according to GCP pricing) is:
- $2.32 at standard pricing
- $1.46 with a one-year commitment
- $1.04 with a three-year commitment
For comparison, GPT-4o costs $10 per million tokens, making DeepSeek V2 up to ten times cheaper. The trade-off is that it doesn’t scale indefinitely, meaning that it may not be as efficient for high-throughput applications.
What people are actually running on their machines
Despite its reputation, most people aren’t actually running DeepSeek R1. Instead, they’re using distilled versions that are fine-tuned from Qwen and LLaMA models.
- DeepSeek-R1:70B is actually LLaMA-70B fine-tuned on DeepSeek-generated reasoning data.
- DeepSeek-R1:32B is actually Qwen-32B fine-tuned on DeepSeek-generated reasoning data.
- The same pattern applies to smaller versions like 1.5B, 7B, 8B, and 14B, which are all finetuned versions of other open-source models.

The original DeepSeek R1 (671B) is simply too large for most real-world deployments.
Can the community modify and release smaller versions?
The short answer is no. The structure of DeepSeek means that removing parameters arbitrarily would break the model. The only way to create smaller versions is through distillation, where a smaller model is trained on reasoning data from a larger one.
Some users are attempting to quantize DeepSeek R1, reducing its precision to shrink the model’s size. The best quantization options currently available reduce it to 131GB, but even then, it still requires 2xH100 80GB GPUs to run at a reasonable speed.
This means that while DeepSeek is open-source, true accessibility is still limited by hardware constraints.
So how are people running these models at all?
Since DeepSeek R1 and V3 are too large for most setups, some users are using offloading techniques to make them work.
With tools like Ollama, part of the model can be stored in system RAM while the active layers are kept in GPU VRAM, shifting them dynamically as needed. This method works particularly well for Mixture of Experts (MoE) models like DeepSeek V3, which only activate a portion of their parameters at a time.
However, even with offloading, you still need a high-memory server, such as:
- 512GB of RAM and an NVIDIA L4 GPU (24GB VRAM)
- Hetzner’s 512GB RAM + RTX 6000 Ada 48GB VRAM setup ($1k/month)
Since the entire model doesn’t fit into VRAM, response speeds drop significantly due to constant memory swapping. In practical terms, this means performance is often limited to just a few tokens per second.
What’s next?
Our take:
- Fine-tuning will become affordable, making AI models more adaptable for business use.
- Model pricing will drop. OpenAI’s o1 and o3 models are expected to become cheaper.
- Every major AI company will release “thinking” models. Anthropic, Cohere, and LLaMA will likely follow.
- Soon, even a GTX 4090 may be enough to run high-quality AI models locally.
- AI models will become easier to optimize and distill, reducing reliance on expensive cloud infrastructure.
DeepSeek proves that high-quality AI doesn’t have to be expensive. While running large models still requires serious hardware, the cost of AI is dropping fast. The ability to fine-tune and host models at a fraction of what it used to cost means that businesses of all sizes can now consider AI solutions that were once only available to big tech companies.