
To fine-tune or not to fine-tune — that’s the tech world’s modern take on poetry, but today we’ll approach it from a slightly different perspective.
The business perspective.
Reading through the tech news daily, you probably encounter frequent mentions of fine-tuning and companies engaged in it.
That’s true, more and more businesses seek to integrate AI into their workflows, but the promise of Large Language Models (LLMs) solving our problems and making our lives easier eventually faces a stark realization:
Foundation models like the one behindChatGPT**aren’t enough to be used in business and you can’t rely solely on them. **
So, is fine-tuning the only way to AI’s promised land? Let’s cover the basics first.
What is fine-tuning in AI?
In the context of AI, fine-tuning is a training technique that takes a model that has already been trained for one given task and then trains it on new data to make the model perform a new specific task.
For example, taking an okay-performing object detection model and teaching it to be an expert dog detector would be fine-tuning it.
But, the dog vs muffin dilemma is probably not the most relevant example to your business.
Fine-tuning an LLM model — example
Harvey AI is a company that fine-tunes and deploys Large Language Models for the legal industry. It’s a particular field with unique terminology and jargon and everything else that makes reading your job contract feel like studying a foreign language beginner’s textbook.
It makes a great case for fine-tuning LLMs because it’s a niche where you want the model to perform very specific tasks such as creating legal documents or performing legal research. Oh, and it also has a ginormous amount of training data.
If you’re a huge law firm like Allen & Overy with access to loads of legal data, you can even train the models on your company’s data to achieve even more tailored results.
Or even on a particular client’s data! In fact, they already do this.

So, based on this fine-tuning example: If I just get all my training data in one place, and feed the model with it, then can I expect the best?
Yes. And no.
If you’re a lawyer, try to type a legal question related to the specific case you’re working on into ChatGPT, and you’ll quickly realize that the results aren’t that helpful or accurate.
In the best case, the answer will raise a couple of eyebrows, in the worst case, you can even go to jail for that.
These models aren’t called large for nothing and fine-tuning them is more intimidating than it may sound at first. There are a couple of dragons to kill on the way from getting your hands on an LLM to having a model tuned to be your business’ expert.
The problems with fine-tuning LLMs
Foundation models, such as OpenAI’s GPT, are trained on diverse datasets to perform well across various tasks.The goal behind training them is to make them versatile, not domain experts, and therefore they struggle with nuanced contexts unique to individual businesses.
To fix that, yes, you can fine-tune a general model on relevant data. But here are the “buts”:
Getting the data for fine-tuning sounds easier than it is
We’re talking thousands of high-quality data points. Even if you are lucky enough to have it, there still is no guarantee you will get the results you are hoping for.
The bigger the model, the more data you will need to fine-tune it. It’s mostly because there are more parameters and variables involved that represent specific bits of information about your data, which need to adapt to the new domain.
Then, the data in question must be high quality, task-specific, and labeled.
What does it mean?
For instance, in the legal field, if you want to create a fine-tuned model that summarizes very long legal documents, a high-quality summary would keep all the specific terminology and relevant information but is concise.
This means you will first need to gather enough training data to teach the model what this specific terminology and relevant information are, and what a “high-quality summary” would look like in your view. In many cases, if no such dataset is available yet, you’d need to summarize all these documents yourself.
The second issue is computational resources
Large models, those that would actually be capable of summarizing long bodies of text adequately, require a lot of computational resources to fine-tune. This may be a limitation, especially for individuals or organizations with limited access to such resources.
Another important aspect is transferability
The success of fine-tuning depends on the similarity between the pre-training task and the target task.
That’s why we refer to the law industry example — the law doesn’t fundamentally change that frequently. Sure, there might be additions to new laws but on a principal level, the law is the law.
However, most businesses nowadays are dynamic and their datasets constantly change. Think about e-commerce stores and their constantly changing inventory, prices, discounts, and so on.
What we learned from customers is that they often want the AI to say X when it says Y. When you’re fine-tuning, it’s very non-obvious how to tweak your dataset to make the AI say Y instead of X.
And also every fine-tuning improvement iteration takes time and money.
There’s also a risk of overfitting
Fine-tuning a Large Language Model can also potentially impact the model’s ability to transfer knowledge across tasks. We call this “overfitting”, where the model becomes overly specialized in the fine-tuning data and performs poorly on new, unseen data.
It’s similar to training a gourmet chef exclusively on making sushi, and then suddenly asking him to bake a chocolate cake.
Instead of a nice dessert, you might end up with a…well, creative and bold but rather disgusting concoction of fish, seaweed, and chocolate — a clear sign of over-specialization!

Another issue is safety
The model might start displaying undesired behavior after fine-tuning , which is especially true of models that have been aligned for safety before the fine-tuning process.
Developers of Large Language Models invest significant effort to ensure that these models don’t generate harmful outputs, such as suggesting illegal activity, and implement various guardrails that prevent [THAT](https://www.the-sun.com/tech/7921201/ai-grandma-exploit-artificial- intelligence-rogue-napalm/) from happening:

To sum up: Fine-tuning may be overkill for your business
So, for many business applications, the fine-tuning process may simply be overkill.
Especially for small to medium-sized enterprises that often lack the resources to fine-tune models effectively.
But more importantly, most business applications, regardless of the size of the enterprise, may just not need a highly specialized expert model.
To illustrate this simply, imagine you open a small business. You will now need to do your taxes. Does that mean you should go through an entire university-level education in Accounting?
No! A few YouTube videos or a “Doing Your Taxes For Dummies” will most probably be more than enough. The same goes for Large Language Model adoption in most business cases.
If you need an AI Agent that will automate your customer support, you don’t need to build a custom model that’s trained on your company’s data and past conversations to achieve outstanding results.
Right… But if we don’t fine-tune, then how can we have this specificity and the level of customization that’s required if we want to use GenAI in a business setting?
We could use a method that lets you add your domain knowledge to the LLM so it gives expert-level responses without the hassle of fine-tuning.
This method is called Retrieval-Augmented Generation (RAG) and it presents an innovative alternative to traditional fine-tuning.
What is RAG in LLM?
Retrieval-Augmented Generation (RAG) is a technique used to optimize the output of Large Language Models (LLMs) by combining pre-trained models, such as OpenAI’s GPT, with a retrieval mechanism that fetches relevant information from a custom knowledge base.
It provides the model with specific information it can use in generating its responses, resulting in much more customized and knowledgeable output.
By leveraging the power of LLMs along with external sources through RAG, users can enjoy greatly enhanced conversational experiences with knowledge bases, overcoming the issue of overly generic responses often encountered with general LLM-based tools like ChatGPT.
Is RAG considered fine-tuning?
Well, Patrick Lewis, currently a research scientist at Cohere, in the research paper in which he coined the term RAG with his co-authors, even called it “a general-purpose fine-tuning recipe”.
But RAG is not considered fine-tuning in the traditional sense.
What is the difference between RAG and fine-tuning an LLM?
As described before, RAG is a technique that combines the processes of retrieving information from a large dataset and generating text based on that retrieved information.
Fine-tuning, on the other hand, refers to the process of taking a pre-trained model and further training it on a smaller, specific dataset to adapt it to a particular task or domain. This process adjusts the weights of the pre-trained model so it performs better on the specific task it has been fine-tuned for.
While RAG can be used in conjunction with fine-tuning — where a model equipped with RAG might be fine-tuned for specific tasks — the RAG process itself is distinct from fine-tuning.
It is more about how the model interacts with external information during the generation process rather than adjusting the model’s internal parameters to better suit a specific task.
Given its different way of functioning, RAG offers additional benefits for businesses.
We can’t ignore the fact that most businesses are dynamic, with industry policies likely to change. RAG lets you be highly adaptable as the retrieval mechanism allows the model to access and incorporate new information easily.
Also in the case of fine-tuning, we mentioned overfitting.
By avoiding task-specific fine-tuning, RAG reduces the risk of it and ensures that the model maintains general language understanding capabilities. It’s crucial to keep that natural, conversational tone of your AI Agent when it’s interacting with your customers.
Moreover, when utilizing RAG, you don’t need to have your own copy of the LLM running on your servers; instead, you can access it as a service.
You don’t need to be knowledgeable in AI to take advantage of the capabilities of RAG and there are many services right now that communicate with an LLM hosted on OpenAI’s, Cohere’s, or Anthropic’s servers. You can leverage the benefits of a pre-trained model along with the ability to retrieve and incorporate external knowledge dynamically.
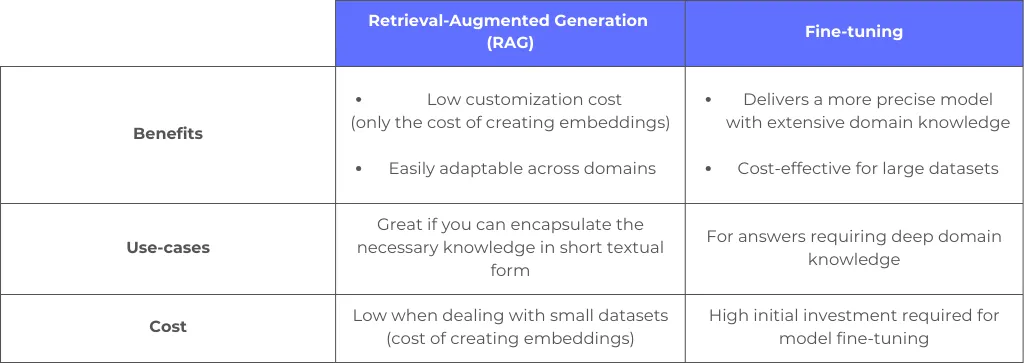
RAG vs fine-tuning: comparison
LLM with RAG example
Imagine you are the owner of ShipIt, a FedEx competitor that offers shipping services internationally. You don’t need to fine-tune an LLM on international trade law if all you want is an AI Agent (a chatbot, if you will) that answers questions about the customs and tax laws of different countries.
If your customers are worried about duties on that AliExpress package from China and ask your AI Agent about it, here’s what happens under the hood if you use this technique.
How does RAG work?
- Firstly, you created a knowledge base for your chatbot that comprises all your customs and import tax documents
- Then, this knowledge base is translated into a format that’s understandable by the model. This process is called embedding. It takes the text you provided and translates it into a vector, a numerical representation, conveying the meaning of the text. You can think of a vector as this arrow in space with some magnitude and direction. Or just as an array of numbers.
- After this process, it’s stored in this form in a vector database.
- Now, when the user asks a question, his query is also converted into this numeric representation, a vector.
- The embedding model then compares this vector to the data that’s in the vector database — so basically to your company’s knowledge base you provided — and when it finds a semantic match, it retrieves the related data, converts it to human-readable words and passes it back to the LLM.
- Finally, the LLM generates the final answer based on the retrieved words and its response to the query and presents it to the user.
It may sound complicated, but you don’t need to know anything about it to use it in your business. As you saw, this approach allows the model to leverage external knowledge without the need for fine-tuning task-specific data.
Is RAG better than fine-tuning for your business?
For most businesses at the stage of exploring how Artificial Intelligence could work for them, fine-tuning is not the best way to go about it.
If you’re a big corporation operating in a specific industry, definitely explore fine-tuning as a way to customize AI and make it aligned with your needs.
But, well, most of us aren’t.
RAG is for those businesses that want to catch the LLM wave without drowning in the complexities of fine-tuning. This makes it a cost-effective solution for businesses that are at earlier stages of adoption of AI.
Using general-purpose Large Language Models together with Retrieval Augmented Generation will allow you to have more flexible and adaptable AI solutions. It may allow you to finally use AI in your business in the first place.
Don’t get left behind.