

LLMs have been able to call tools for a while, but Model Context Protocol (MCP) brings a structured, standardized way to do it.
Yet, there’s still confusion about what MCP actually is.
Many assume MCP is an app, an API, or some tool, but it’s none of these. It’s a protocol, and that means something very specific.
Let’s break it down.
If you just want to see what MCP unlocks in practice, check out this short video:
What is a protocol?
A protocol is simply a set of rules that define how two or more systems communicate with each other.
It doesn’t do anything by itself. It just defines the structure and expectations of a conversation between two entities. Think of it as a shared language with strict grammar rules that computers follow to exchange information.
Postal systems do something similar. All postal offices in any given country follow a standardized address format to send letters.
Or think of it like USB-C for AI tools. Twenty years ago, the market was flooded with different types of charging and data cables. Just like AI ecosystems have had multiple ways of passing tools to language models. Frameworks like LangChain, Haystack, and Pydantic AI all defined their own formats for integrating tools, meaning that if a developer wanted to write a toolset for Google Maps, they had to do it for each specific technology.
To make this more concrete, let’s look at the most popular protocol, HTTP (Hypertext Transfer Protocol), that powers websites. HTTP defines, among other things, how a browser (client) requests a webpage from a web server and how the server should respond.
Here’s an example of an HTTP request-response cycle:
- Browser makes an HTTP request
When you type https://example.com into your browser, the browser sends a structured HTTP request to the web server:
Here are the HTTP parameters and values used in our example:
"GET" – This is the action (requesting a webpage).
"/index.html" – The specific webpage being requested.
"HTTP/1.1" – The version of the protocol being used.
"Host: example.com" – The domain name of the website.
"User-Agent: Mozilla/5.0" – Information about the browser making the request.The web server knows how to interpret this request because HTTP standardizes this format. It understands this “language.”
- Server Responds Using the HTTP Protocol
The server processes the request and sends back a structured HTTP response:
"HTTP/1.1 200 OK" – The response code (200 means success).
"Content-Type: text/html" – The type of content being sent back.
"Content-Length: 512" – The size of the response.
HTML Content – The actual webpage content (there's just a "Welcome to Example.com" headline)Important: HTTP itself does not store web pages or display them. It just defines the rules for how web browsers and web servers are allowed to communicate. Any system that follows those rules can communicate over the HTTP-defined Internet.
How MCP works as a protocol
Now, let’s apply the same thinking to MCP (Model Context Protocol).
MCP is a protocol for AI agents to talk to external tools and data sources. Like HTTP, it doesn’t store data or execute tasks itself. It simply defines a standardized way for AI to request and retrieve information from tools.
What are those “tools,” you might ask?
In the context of LLMs, tools are external systems, APIs, or services that AI can interact with to extend its capabilities beyond just text generation. They allow AI agents to fetch real-time data, book appointments, or text your friends, making they far more useful for real-world needs.
Let’s say you ask an AI agent:
“What time is it in London right now?”
Since the AI itself doesn’t know the right answer, as AI models have a knowledge cutoff date (October 2023 for OpenAI’s models), it needs to fetch live data from a time service. But instead of using HTTP to request a webpage, the AI uses MCP to request time data.
Here’s what happens:
- AI agent makes an MCP request to the time service (example)
"method": "tools.call" → The AI is calling an external tool.
"tool": "get_time" → The name of the tool it wants to use.
"args": { "location": "London" } → The specific input parameters.Just like in HTTP, this request follows a strict format so that any MCP-compatible tool knows exactly how to interpret it.
- MCP time server responds
The external tool (time server) follows MCP’s response rules and sends back:
"status": "success" → Confirms the request was processed correctly.
"result" → Contains the actual time data.Now, the AI agent can take this data and compose an actual response to the user with:
“The current time in London is 12:20 PM (GMT).”
To summarize and clear up confusion:
“MCP is an app.” → No, MCP is a set of rules. You need AI software and tools that implement MCP to actually use it — just like how the Instagram app needs live Instagram servers to respond to HTTP requests and deliver data.
“MCP is a database.” → No, MCP doesn’t store data. It helps AI agents talk to databases or APIs.
“MCP is like an API.” → Not exactly. An API is a specific way to interact with one system, while a protocol (like MCP or HTTP) defines a universal way that many different systems can communicate. MCP is a language an AI system can use to interact with many actual APIs (time, databases, Stripe, Slack, etc.).

Why MCP is exciting
Now that we know MCP is a standardized way for AI software to interact with external tools and apps, and that MCP isn’t an API, let’s understand why the AI developers community (us included) got excited about it.
Since MCP isn’t an API but rather allows AI apps to interact with actual APIs at scale, it helps projects that require connecting to many external systems get off the ground faster. To do this, developers would sometimes need to go through a full API integration development cycle, but today, they usually use existing libraries or open-source projects (for example, available on GitHub) that provide the needed functionality.
Using these libraries jump-starts development, but integrating them properly with your system (if it’s not compatible with the implementation you found on GitHub) still requires effort to make the tool work with the AI.
With MCP, once the framework is in place, adding a new integration (say, integrating Google Drive) might be a matter of connecting to the Google Drive MCP server with a few lines of code. You won’t encounter compatibility issues because you both use the same protocol: MCP.
Let’s compare both approaches to see the differences more clearly.
Standard integration vs. using Model Context Protocol (MCP)
To make this comparison concrete, let’s walk through adding Google Drive file access to an AI assistant, first manually and then with an MCP-compatible tool.
Standard integration
-
Find & adapt a library: You search for a Google Drive API client or open-source project. Google provides client libraries (e.g. Google Drive API for Python); you include this in your project. You still need to ensure it works with your AI’s environment.
-
Implement the logic: You write functions to, say, search for files or fetch a document from Drive. The AI, when it needs something, must call these functions. You format the AI’s request into the Google Drive-specific API calls. After getting a response from Google, you extract the content to pass back to the AI’s context.
-
Handle errors and edge cases: Add code to handle cases like “file not found,” permissions errors, or API rate limits. If Google’s API returns an error, you catch it and maybe respond with an apologetic message or ask the AI to rephrase. You also need to guard against your AI sending too many requests too quickly.
-
Maintain: Over time, if Google updates their API or the library, you must update your code. If you find a bug in the library, you might have to patch or find another source. You essentially become the maintainer of this Google Drive integration within your AI application.
This process extends to other tools: want to add Slack or a database to your AI? You need to repeat the whole process for each.
MCP integration
Now let’s see how that process would look like when using MCP.
First, let’s define key concepts:
Client – an AI application (ChatGPT, Claude app, Quickchat AI) that establishes a connection to one or more servers and requests information or actions to perform tasks prompted by a user.
Server – Each server might connect to something like a database, an API (Google Drive) and define a set of “tools” or data that it can provide. In this case, server is a program that exposes these tools and capabilities to the Client (AI app).
Developers — depending on what they want to do — can choose to be on either side: build a server to expose data, or build an AI client that can talk to any servers. Most want the second option, but still let’s start with the server side to understand how MCP works step by step:
-
Initializing an MCP server. A developer or system admin sets up an MCP server for a given tool or data source. An MCP server is usually just a small program that implements the MCP specification. For example, there’s a pre-built Google Drive MCP server available that knows how to search and fetch documents.
When initializing the server, you give it access to the target system (Google Drive). The server then exposes a set of tools corresponding to actions or queries it can handle. It’s essentially an API adapter speaking MCP on one side and the native service on the other side.
Once the server is running, it awaits requests.
-
Connecting an LLM (client) to an MCP server. Next, the AI application (the “client” side) needs to connect to that server. In practice, if you’re using an AI platform that supports MCP (such as Claude Desktop), you’d configure it with the address or command to start the server. Once connected, the client establishes a session with the server following MCP’s handshake. If you’re using Claude’s interface, you’d see that Claude is “connected” to certain MCP servers (the UI might indicate available connectors).
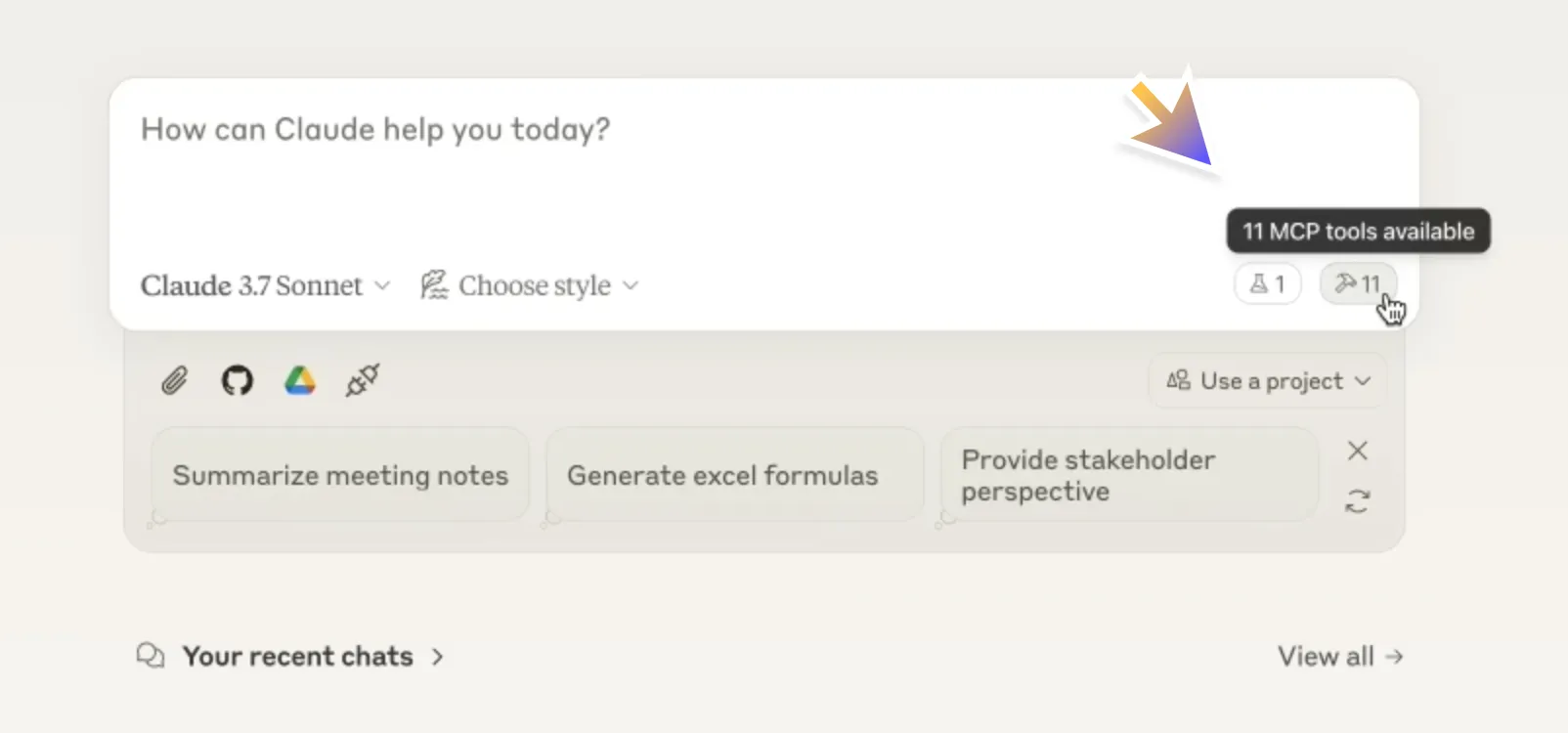
That’s how it looks in Claude UI
-
Discovering available tools. With the connection established, the first thing to do is find out what the server offers (sometimes, it happens automatically after you connect to the server). The MCP client sends a tools/list request to the server (this is defined in the protocol). The server replies with a list of its available tools, each with details like name, description, and input schema.
For example, a server might respond that it has create_file(path, content), read_file(path), and search_files(query) tools available. The client then makes this information available to the LLM. In many implementations, the client will format these tool descriptions and include them in the model’s context (for instance, adding to the system prompt: “You have access to the following tools… [tool list]”).
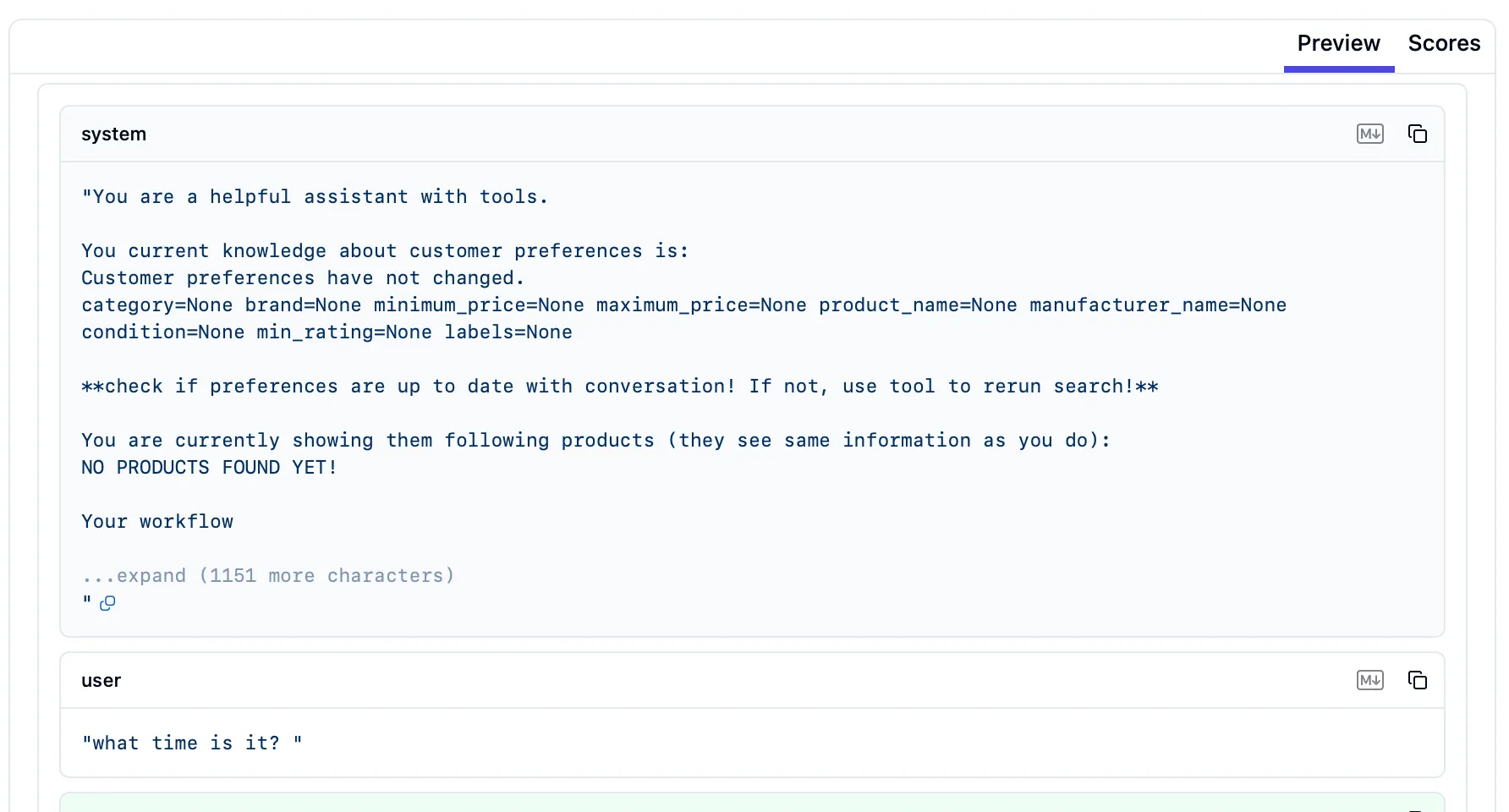
Here’s an AI system prompt along with the user’s message requesting the current time
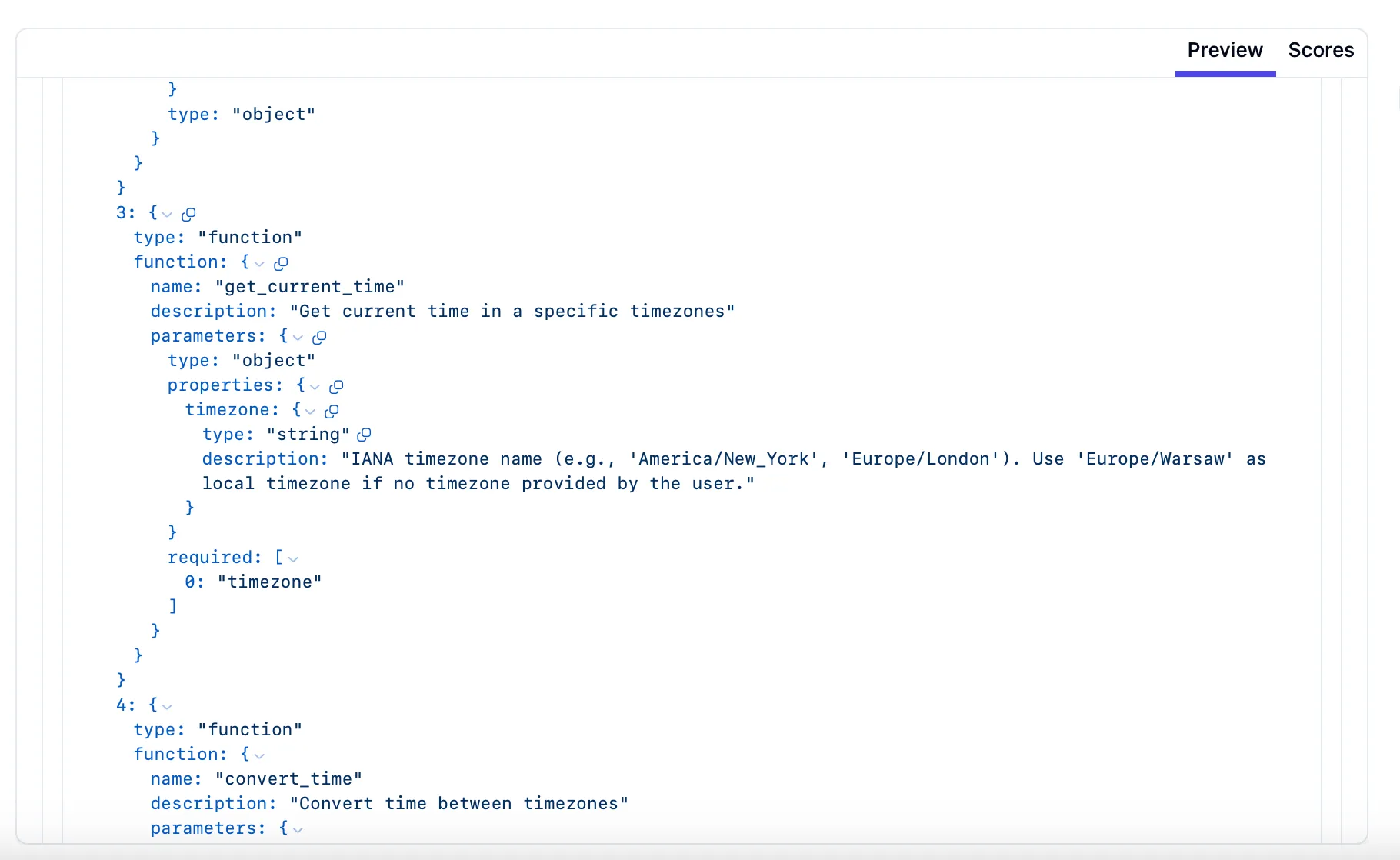
With MCP tools implemented, a tool called “get_current_time” is integrated, allowing the AI to access an external resource and fetch the exact time in London
This means you don’t need to pre-think and program in all potential actions your AI app might need to complete some task. With MCP, the AI can discover all the possible actions on the fly by asking an MCP server and choose whatever is needed.
-
Using a tool through MCP. When the AI needs to perform an action or fetch data, it will invoke a tool via MCP. From the AI’s perspective (especially for models like Claude that natively support tool use), it will decide in its reasoning: “I should call tool X with these parameters.” The MCP client captures that intention and sends a tools/call request in the MCP format to the appropriate server (Google Drive MCP server).
-
The MCP server acts as a bridge. It receives a structured MCP-compliant request from the AI agent, maps it to the correct Google Drive API endpoint, rewrites the request into an actual Google Drive API call, executes the request, processes the response, and reformats it into an MCP-compliant response again before sending it back to the AI agent.
What’s worth noting is that MCP servers follow a structured approach to handling errors, ensuring that AI Agents can interpret and act on them effectively.
Let’s say an AI Agent is using an MCP tool to find a file in Google Drive. If the request includes an invalid file ID (e.g., a five-character-long string instead of the expected format), the MCP server will return an error message:
Rather than simply failing, the AI Agent can take this structured response and reframe it into user-friendly feedback:
“It looks like the file ID you provided is too short. Google Drive file IDs are typically 28 characters long. Could you double-check and try again?”
This approach ensures that errors don’t lead to dead ends and instead become opportunities for the AI Agent to guide the user toward a successful resolution.
-
Answering the user’s question/request. Once the MCP server returns a result, the MCP client hands that data back to the AI app. The model then incorporates the result into its reasoning or directly into the output it generates for the user.
If the user requests the creation of a new Google Sheets file, the server’s reply (containing the file ID and a generated link) will be fed into the model. The model will then respond to the user with: “Good news! Your new Google Sheets file is ready. You can access it here: [link].”
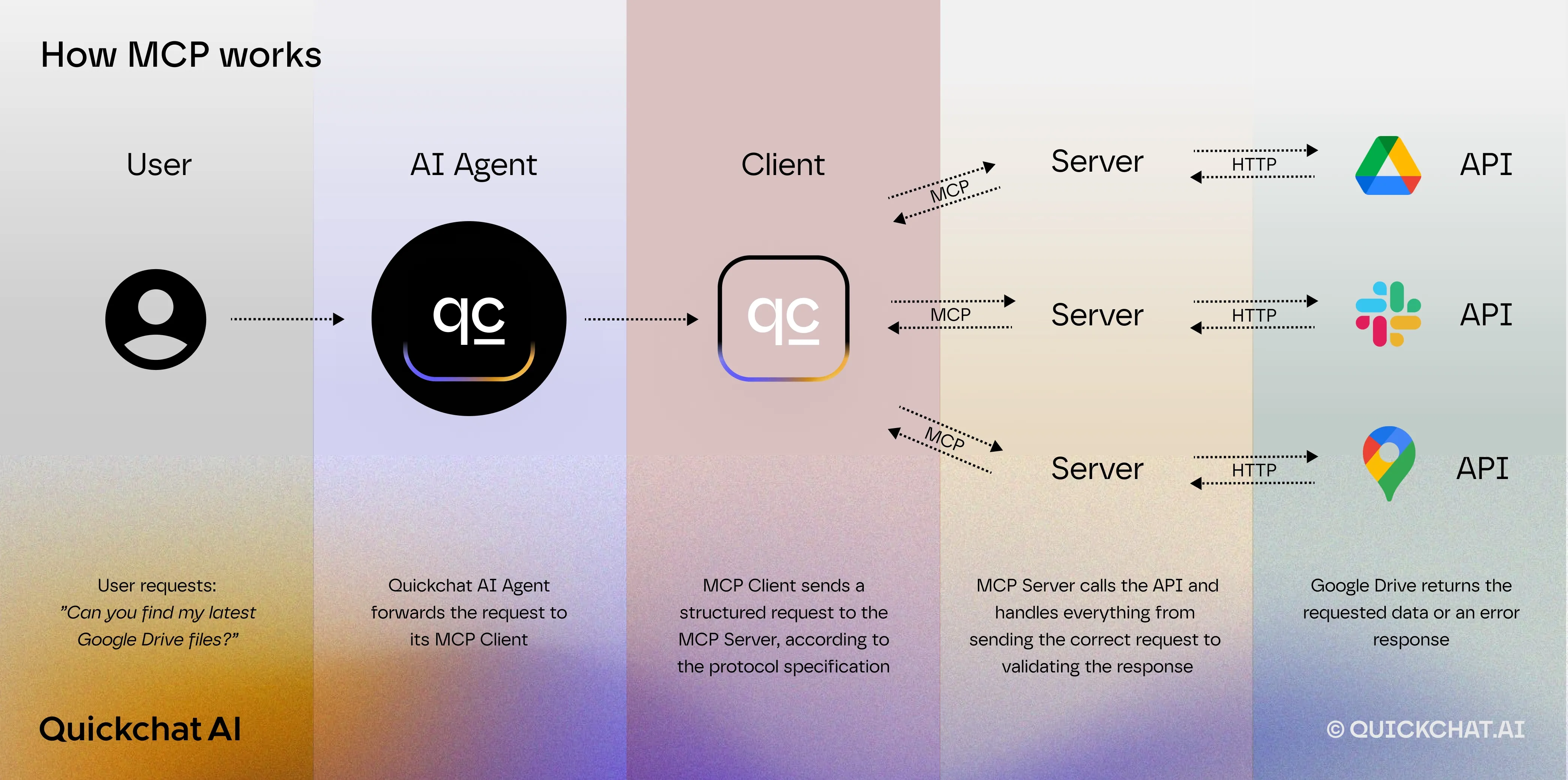
Throughout this process, the AI remains in control of the flow: it decides when to call a tool and how to use the result in forming its answer. Meanwhile, the developer doesn’t have to manually orchestrate these steps – the MCP framework and the AI model handle it. The end result is that the user can ask the AI complex questions or tasks that require external info or actions, and the AI can autonomously carry those out via MCP and give back a result.
Benefits of using an MCP
Notice how this approach abstracts away many details: the client did not handle API keys or HTTP status codes – those are handled by the MCP server.
The main point is the simplicity at the integration point: we “ask” for customers, and we get them. The logic of how to fetch them is encapsulated elsewhere. It means a developer working on the AI side doesn’t need to write new HTTP calls for each new action – they just invoke tools by name. The heavy lifting (auth, calling Google Drive’s endpoints, formatting the response) is done in the MCP server code, which is reusable and standardized.
Here’s a summary of the key benefits:
-
Reduces API-specific glue code. Before MCP, making an AI use an external service typically required writing a bunch of “glue” code: calling the API, transforming the response into text the model can digest, then parsing the model’s output to maybe call another API, etc. With MCP, much of that glue is eliminated. The model’s client and the server handle data exchange in a structured way, so you don’t need to manually transform other formats (like JSON) to text or vice versa – the protocol does it. You also don’t have to write logic to decide when to call what. The AI (guided by the tool descriptions and its own reasoning or prompt) does it.
-
Reusable, shared connectors instead of one-off API wrappers. With MCP, you write an integration once and can reuse it across many projects and AI systems. For example, you could create an MCP server for your company’s internal wiki. Any AI app that supports MCP can connect to that one server to query the wiki. You don’t need to re-implement “wiki search” for each new AI chatbot or each different LLM vendor. This reusability is a shift from the past where every team might write their own slightly different integration for the same API. MCP encourages a library of connectors that can be shared and improved collectively.
-
Plug-and-play integration with different LLMs. MCP is model-agnostic. The protocol doesn’t care if the client is Claude, GPT-4, DeepSeek, or any future model – as long as the client can handle the MCP interface. In the future, if you want to switch to another model, you can do so without rewriting all your integrations.
-
Easier maintenance. Because it’s an open standard, there’s a growing community contributing pre-built servers (for databases, popular APIs, etc.) that you can leverage rather than building from scratch. As you integrate more systems, MCP helps avoid the “spaghetti” of many point-to-point integrations. And you don’t need to monitor all the API updates from other providers.
Will API integrations become obsolete?
Both traditional API integrations and MCP have their place. The best approach can depend on the project’s nature, team expertise, and long-term goals.
If you only need to integrate with one or two external services and the interactions are relatively straightforward, a direct API integration is often the quickest solution. If your web app just needs to verify a Stripe payment token on checkout, calling Stripe’s API directly is simple and effective. Introducing MCP in this scenario might be overkill.
In cases where you need very tight control over the request/response (for performance tuning, special data handling, or proprietary protocols), writing directly to the API can be better. Traditional integrations let you use all advanced features of an API and tailor the calls exactly. If an API has unusual requirements or if you want to avoid any abstraction layer for maximum clarity and control, traditional is appropriate.
List of available MCP servers
If you want to get started with MCP, check out the MCP servers directories below:
FAQ
Does it only work with Claude?
MCP is model-agnostic. The protocol doesn’t care if the client is Claude, GPT-4, a local LLaMA derivative, or any future model – as long as the client can handle the MCP interface. This means you are not locked into a single AI provider when you build your tool integrations.
How does MCP differ from just giving the model all the info it needs up front? Why not stuff the prompt with data instead?
MCP is fundamentally different from stuffing the model’s prompt with data because it allows the model to fetch information dynamically when needed, rather than working with a static, preloaded prompt. Stuffing text in the prompt runs into limitations, as AI models have a fixed context window, meaning too much data can cause important details to be lost, slow down responses, and increase API costs (because of per-token pricing models used by LLM vendors). It also only provides knowledge at a single point in time, while MCP enables real-time access to live external data and lets the AI take action, not just read information. An AI with a packed prompt might know customer details but won’t be able to update records or process transactions.
What if we connect dozens of tools to the AI? Won’t that overwhelm the model or cause it to misuse them?
It depends on the implementation, but it’s true that current LLMs have limits in how well they distinguish and choose between many options. If you present a model with, say, 50 possible tools, there’s a risk it might pick the wrong one. The MCP approach itself doesn’t force you to load everything at once. You should connect relevant tools based on the context. A best practice is to only connect the tools that are needed for the task/domain at hand and leverage multiagent collaboration — a sort of tool routing or an agent that first decides which subset of tools to consider.
MCP vs Function Calling
Traditional function calling (as seen in OpenAI’s API or other LLMs) allows a developer to define a set of functions, give their definitions to the model, and have the model “call” them by name with arguments. This was a big step for AI integration, but it has limitations. One major difference is when and how tools are defined. In classic function calling, all possible functions must be declared upfront (at design time) in the prompt or through the API. The model can only call those fixed functions. In MCP, tools are discoverable at runtime – the AI can query what’s available and even get new tools mid-session.
MCP vs GPT Actions & Plugins
GPT Actions/Plugins refer to OpenAI’s ecosystem where you could enable plugins (like a web browser, or a PDF reader) for ChatGPT, or the “GPTs” (custom ChatGPT agents) that can have tool usage. Those were exciting, but they required custom development for each plugin and were limited to OpenAI’s platforms. If you wanted a ChatGPT plugin for a task, you had to create an API and a manifest, and go through OpenAI’s approval or at least enable it manually. Each plugin was essentially a silo – a weather plugin, a travel plugin, etc., each with its own endpoints and logic. MCP improves on this concept by unifying and opening it up.
MCP vs RAG (Retrieval-Augmented Generation)
Retrieval-Augmented Generation (RAG) is a technique where an LLM is supplemented with an external knowledge base. Typically, RAG involves a vector database or search index: the user’s query is used to fetch relevant documents or data (by semantic search or other methods), and those documents are provided to the model as additional context to “read” when forming an answer. RAG is about giving the model knowledge it didn’t originally have, especially helpful for factual QA or domain-specific info. However, RAG is read-only – the model retrieves text passages, but doesn’t perform actions beyond retrieval.
MCP, by contrast, is about taking actions or performing arbitrary operations, not just retrieving informational context. With MCP, an AI can do things: write to a database, send an email, execute code, etc. It’s not limited to fetching knowledge; it can trigger changes in external systems. So in many ways, RAG and MCP serve different purposes.