

Large Language Model (LLM) benchmarks have become the battlefield of competing LLM vendors and research labs. Basically, everyone is trying to show that their model is the best…
But is it really that easy to say which LLM is better than others?
Let’s talk about what benchmark datasets are, and what’s the issue with the LLM leaderboard.
What are LLM benchmarks?
What we refer to as “LLM benchmarks” are essentiallybenchmarking datasets (not to be confused with benchmark models).
The goal of benchmarking LLMs is to see if we can create a model that beats published results on a given dataset by completing a standardized set of tasks.
A so-called state-of-the-art model is the best one on a given dataset for a given problem. It’s the title the fight is for.
There are quite a few benchmarking datasets for general-purpose LLMs, so let’s first get familiar with the most common ones before we start discussing some issues with the LLM leaderboard.
What are the most common LLM benchmarks?
Massively Multitask Language Understanding dataset (MMLU)
The first one is the Massively Multitask Language Understanding dataset, MMLU for short. This benchmark dataset for LLMs measures general reasoning and comprehension acquired by models during pre-training. It consists of 57 categories of knowledge spanning Humanities, Social Sciences, STEM, and more.
Here’s an example — a question from the Microeconomics category:

WinoGrande
Then there’s Winogrande that’s another dataset for common-sense reasoning, formulated as binary fill-in-the-blanks tasks which require common sense to get correctly.
An example from the dataset could be:

HellaSwag
The next one, HellaSwag, is a challenge dataset for evaluating common- sense natural language inference that is especially hard for state-of-the-art models, though its questions are trivial for humans.
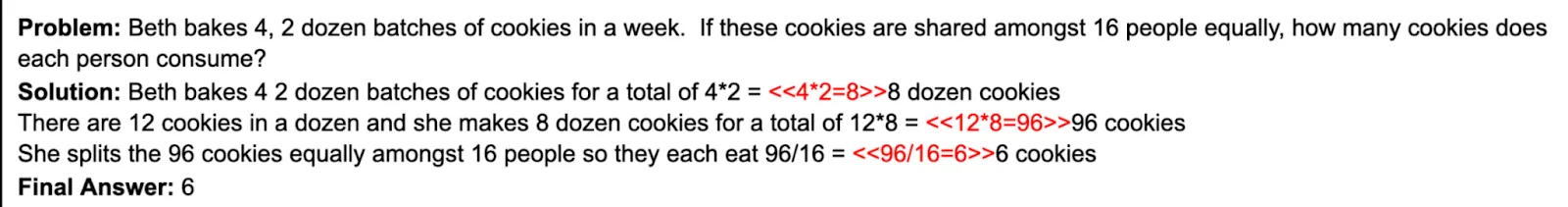
GSM8K
We also have GSM8K which assesses the mastery of grade school math…

HumanEval
And HumanEval that’s used to evaluate the functional correctness of model- generated code, for example:
These are some of the most popular LLM benchmarking datasets, but there are basically as many ways to evaluate LLMs nowadays as there are LLMs themselves.
The issue is that when the industry itself is both a currently researched frontier of science and a business opportunity, a conflict of interest arises. On the one hand researchers “just” want to figure AI out — on the other hand, companies start competing for customers, and happily overuse “The Best LLM” title.
That brings us to the next point:
Which LLM (if any…) is the best?
There’s no denying that LLM benchmarks provide a standardized way to measure the performance of LLMs across various tasks. They are the only way to guide practitioners on which model to choose, without actually testing every model themselves.
Plus, they quantify the immense progress the field is making day by day.
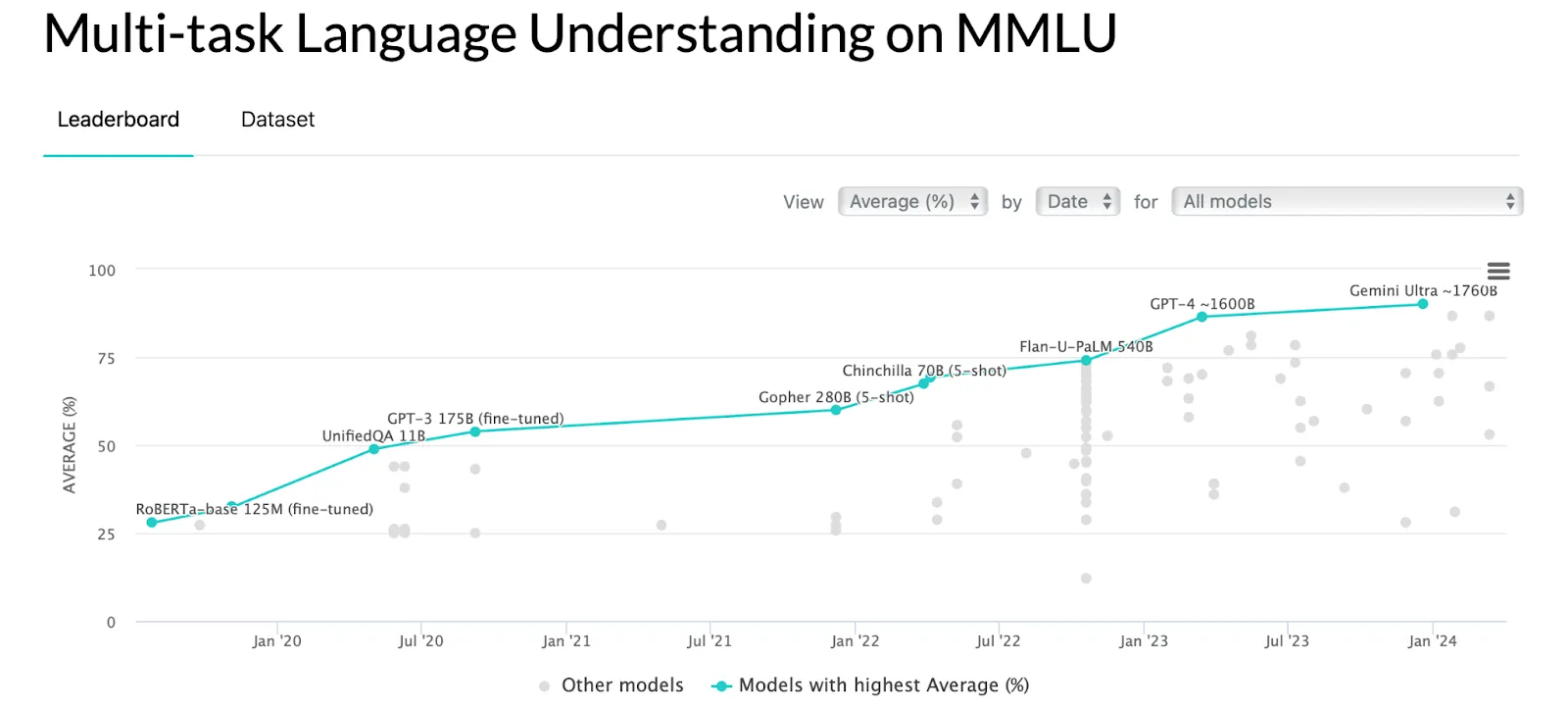
Source: https://paperswithcode.com/sota/multi-task-language-understanding-on- mmlu
However, since AI became trendy and started attracting a lot of attention, everyone is keeping their eyes peeled on LLM benchmarks to see which LLM is better than others — just like they were watching gladiators fight in an arena.
This has sparked an unfortunate trend in which the top of the LLM performance benchmarks become the target, causing research labs and BigTech to compete to market their models as state-of-the-art.
How to make sense of the LLM leaderboard? Don’t buy everything that you read online. Here are some things to keep in mind before you start reading the tech news or your LinkedIn feed again.
Problems with the LLM leaderboard
BigTech reported results should be taken with a grain of salt, because, well… Proprietary models can’t usually be fairly compared to their competitors.
An example?
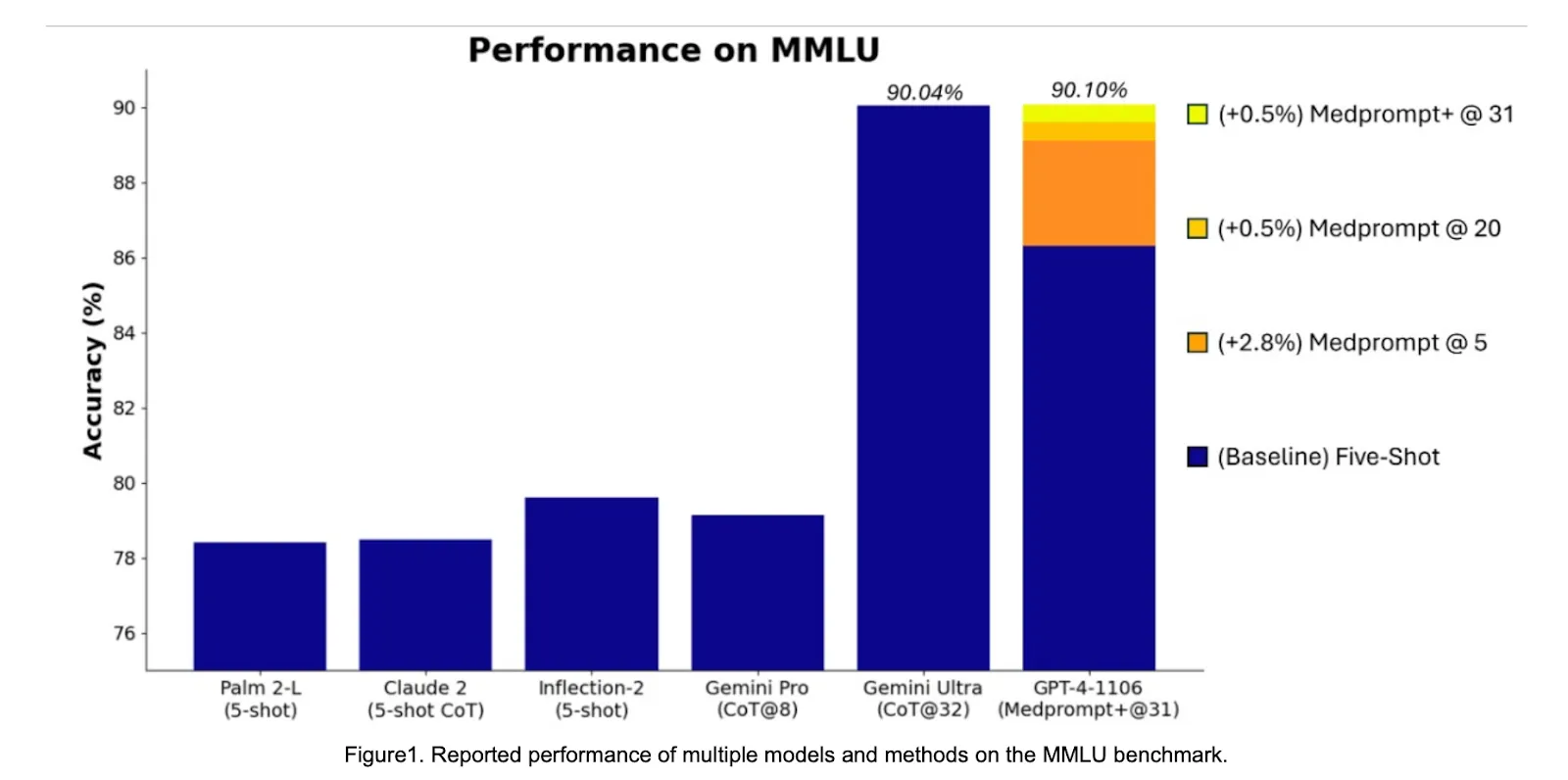
A couple of days after the Gemini model suite was released by Google, amongst them Gemini Ultra, the [Microsoft-OpenAI coalition responded](https://www.microsoft.com/en-us/research/blog/steering-at-the- frontier-extending-the-power-of-prompting/) that GPT4 beats Gemini Ultra on a popular benchmark MMLU, by using a new prompting technique called Medprompt.
The problem here though is that Gemini’s score on MMLU using Medprompt was never reported and we have no clue what the score would have been using this novel prompting technique.
This might have well passed as an interesting contribution to the world of prompting techniques but OpenAI/Microsoft seems to try and one-up Google by announcing the GPT4 shows performance improved by 0.06% compared to Gemini Ultra. The truthfulness of this performance cannot really be verified without more access to the model weights.
Source: https://www.microsoft.com/en-us/research/blog/steering-at-the- frontier-extending-the-power-of-prompting/
We are not defending either of these BigTech companies here, they are both guilty of bending evaluation scores to fit their narrative.
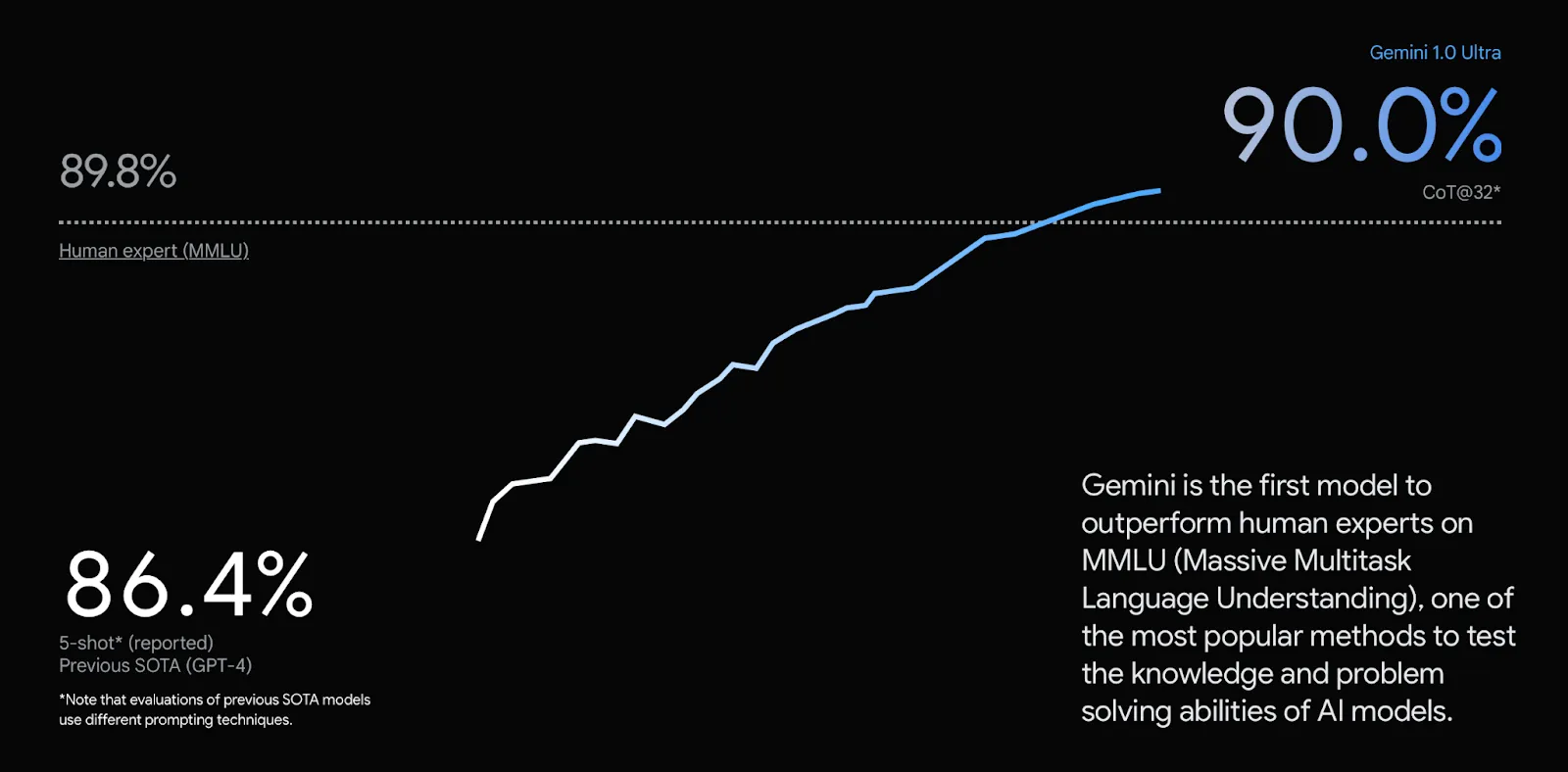
Here’s another example. Gemini 1.0 Ultra announces it’s the first model to outperform human experts and the previous SOTA GPT-4 but, again, we have no way to reproduce these results as we don’t have access to the model weights.

Sensitivity of LLM benchmarks
Another thing to keep in mind is that LLM performance benchmarks are sensitive and with scores not being standardized, companies might publish the single best score which doesn’t reflect performance robustly.
A recently published paper ” When Benchmarks are Targets: Revealing the Sensitivity of Large Language Model Leaderboards” shows that for popular multiple-choice question benchmarks (like MMLU) minor perturbations to the benchmark, such as changing the order of choices or the method of answer selection, result in changes in rankings up to 8 positions.
Taking this instability into consideration, how significant and trustworthy are the results reported by the industry?
For example, the best Claude 3 model achieved 0.4% better accuracy on some datasets than GPT-4. Yet, it’s hard to compare it really, since they don’t report whether this is an averaged result over N runs or a best-selected result.
What to trust when the LLM benchmark becomes the target?
Don’t reject LLM benchmarks, they are great indicators of the immense progress of the field. They’re a standardized way to measure performance and the only guidance for choosing models without personally testing each one.
But… Take the LLM benchmark results with a grain of salt. The 0.4% advantage some model has above another could just be a marketing trick.
There are ways to compare the models and pick the best LLM for your needs, though, which we’re going to cover in the next article.