

AI Breakthroughs
Artificial Intelligence has come a long way in the past decade. We have seen breakthroughs in computer vision, natural language processing, and game playing, to name a few. One of the common factors among these breakthroughs is the use of large amounts of accurately labeled data.
In this blog post, we will take a closer look at some of the recent AI breakthroughs and how self-supervised learning has played a significant role in these advancements. We will also explore how the field is moving towards an all-embracing “look at history and predict the future” setup, and how that shift is impacting business use cases of Machine Learning.
2012 - The Krizhevsky, Sutskever, Hinton ImageNet breakthrough
 Sample from the ImageNet dataset(source)
Sample from the ImageNet dataset(source)
One of the earliest breakthroughs in AI was the 2012 ImageNet moment, where a deep neural network called AlexNet achieved a top-5 error rate of 15.3% (more then 10 percentage points improvement over previous results) on a dataset of over 14 million images.
It was a game-changer in the field of computer vision, as it showed that deep learning could vastly outperform traditional image recognition methods. It also led to widespread adoption of deep learning in computer vision tasks, and the ImageNet dataset remains a benchmark for image classification models to this day.
Today, you can access the 14,197,122 manually labelled images on the dataset’s website.
2013 - The DeepMind Atari breakthrough (game self-play)
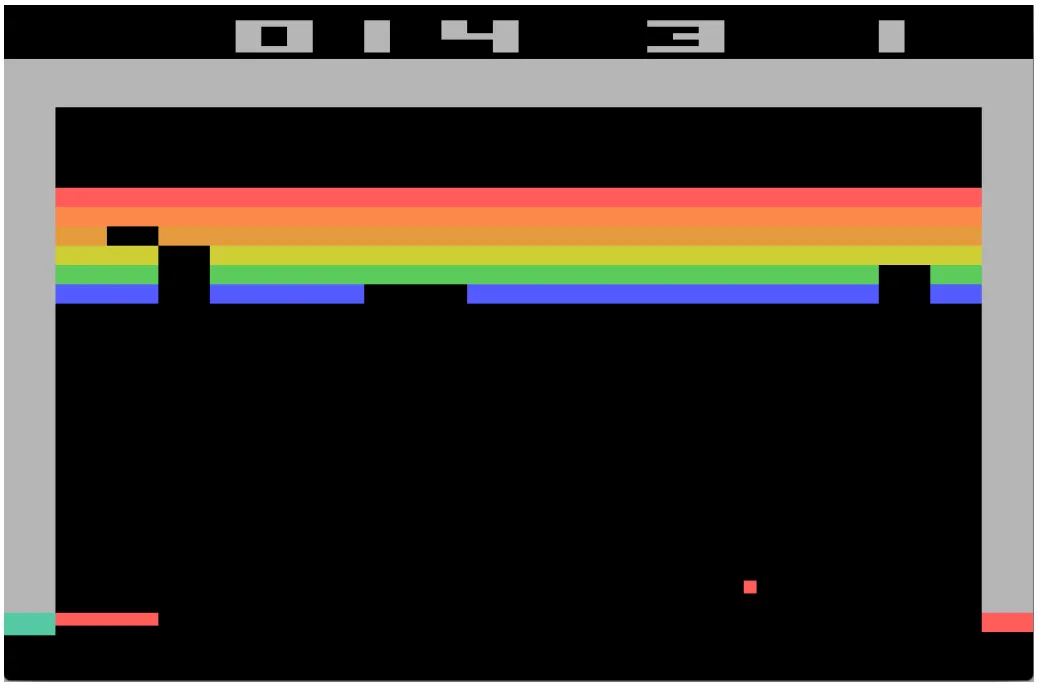 Breakout screenshot from the Deepmind Atari paper
Breakout screenshot from the Deepmind Atari paper
In 2013, DeepMind made a breakthrough in game playing with their AI agent that learned to play Atari games using reinforcement learning , a type of unsupervised learning.
2016 - The DeepMind AlphaGo breakthrough (game self-play)
 The next game DeepMind went after was Go
The next game DeepMind went after was Go
In 2016, AlphaGo, another game-playing AI agent developed by DeepMind, achieved a breakthrough by using a combination of supervised and unsupervised learning. In March 2016, AlphaGo beat Lee Sedol (world’s top Go player) 4:1 in an uprecedented event - often compared to the chess match between Deep Blue and Garry Kasparov in 1997.
2020 - GPT-3 (scrape the internet and predict the next word / token)
In 2020, GPT-3, a language model developed by OpenAI, made a breakthrough by using unsupervised learning on huge amounts of text data scraped from the Internet. The model was trained on the task of predicting the next word or token in a sentence. GPT-3 is based on the transformer architecture. It can generate very coherent and human-sounding text. GPT-3 was trained on a massive dataset of unlabelled data and has been used as a base model to create other models like ChatGPT.
2022 - DALL-E-2, Stable Diffusion (scrape the internet for image – alt- text pairs)
 Image has been generated with Stable Diffusion 2.1 using prompt: ‘Futuristic humanoid robot in front of a waterfall taking off using a jet pack, fireworks in the background, high-resolution photograph with great lighting’
Image has been generated with Stable Diffusion 2.1 using prompt: ‘Futuristic humanoid robot in front of a waterfall taking off using a jet pack, fireworks in the background, high-resolution photograph with great lighting’
In 2022, DALL-E-2, another model developed by OpenAI, made a breakthrough by using self-supervised learning on image <> alt text pairs scraped from the Internet. Stable Diffusion (try it out here), an open- source model followed soon after.
Next AI breakthrough?
Self-supervised learning has been a significant factor in recent AI advancements. Crucially, it allows AI models to learn from large amounts of unlabeled data , which can be obtained orders of magnitude faster than labelled data (compare game self-play or scraping text off the Internet to manually annotating text or images).
That is particularly relevant in today’s digital world, packed full of vast amounts of data in the form of videos (think of TikTok, Netflix, GIFs). It must be that the next breakthrough comes from a predict what happens next in this video setup.
It all comes down to data
All of the above seem to be converging to an all-embracing look at history and predict the future setup. We’ve been observing this shift in business use cases of Machine Learning for a while now:
- online advertisers accumulate user profiles rather than do one-off predictions of click-through rates,
- the same thing happens with Machine Learning for transaction fraud detection: all users get profiled over time based on their financial data,
- Spotify, YouTube, Netflix, etc. will show you recommendations that fit how your profile has been evolving and lead to where you want to go next rather than those that maximise the immediate click probability.
It all comes down to generating a huge amount of accurately labelled data. And there’s no greater dataset than all of what has happened so far and no more accurate label than seeing what happened next.